Scaling and Large Topologies
Scaling and Large Topologies Recipe
- Use clusters to scale horizontally and vertically, and to support failover and easier administration. If using WAS >= 8.5, consider using dynamic clusters.
- Very large topologies also employ multiple cells for the same application(s). This allows for deployment of new application versions or configurations to only one of the cells; if the change breaks, it affects only that cell. Multiple cells can be problematic if significant database schema changes are made.
- If using the High Availability Manager or any functions that require it (e.g. EJB WLM, SIB, etc.):
- Processes such as application servers and node agents must be in the same core group, or part of bridged core groups.
- In general, the number of processes in a single core group should not exceed 200. Practically, this number is limited by the CPU usage, heartbeat intervals, and number of available sockets.
- The members of a core group should be on the same LAN.
- The members of a cell should not communicate with one another across firewalls as that provides no meaningful additional security and complicates administration.
- Create dedicated preferred coordinators for a core group with a large default maximum heap size (e.g. -Xmx1g).
- If using core group bridges, create dedicated bridge servers with a large default maximum heap size (e.g. -Xmx1g).
- Start or stop groups of processes at the same time to reduce the effects of view changes.
- Change the HAM protocols to the latest versions: IBM_CS_WIRE_FORMAT_VERSION and IBM_CS_HAM_PROTOCOL_VERSION
- If you are not using the High Availability Manager, it is not recommended to disable it, but instead to create multiple cells or bridged core groups.
Clusters
Clusters are sets of servers that are managed together and participate in workload management. Clusters enable enterprise applications to scale beyond the amount of throughput capable of being achieved with a single application server. Clusters also enable enterprise applications to be highly available because requests are automatically routed to the running servers in the event of a failure. The servers that are members of a cluster can be on different host machines.... A cell can include no clusters, one cluster, or multiple clusters.
Servers that belong to a cluster are members of that cluster set and must all have identical application components deployed on them. Other than the applications configured to run on them, cluster members do not have to share any other configuration data. One cluster member might be running on a huge multi-processor enterprise server system, while another member of that same cluster might be running on a smaller system.
A vertical cluster has cluster members on the same node, or physical machine. A horizontal cluster has cluster members on multiple nodes across many machines in a cell. You can configure either type of cluster, or have a combination of vertical and horizontal clusters.
Dynamic Clusters
WAS 8.5 includes Intelligent Management which provides dynamic clusters. Dynamic clusters provide the same functionality of traditional clusters and more. See the Intelligent Management section.
Large Topologies, High Availability Manager
The latest guidance on core group size is: "Core groups containing more than 100 member should work without issue in many topologies. Exceeding a core group of 200 members is not recommended." (http://www-01.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/crun_ha_cgscale.html). If the size of your core group is too large, consider core group bridging: http://www-01.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/crun_ha_coregroupbridge.html
It is a best practice to use the newer High Availability Manager (HAManager) protocols, particularly with large topologies (http://pic.dhe.ibm.com/infocenter/wasinfo/v8r5/topic/com.ibm.websphere.nd.multiplatform.doc/ae/crun_ha_protocol_ver.html):
- IBM_CS_WIRE_FORMAT_VERSION=6.1.0
- IBM_CS_HAM_PROTOCOL_VERSION=6.0.2.31
In general, for small core groups, HA/DCS issues are just symptoms of other issues like CPU exhaustion, network instability, etc. Some other things to consider:
- Set a preferred coordinator: "Remember that coordinator election occurs whenever the view changes. Electing a new coordinator uses a lot of resources because this process causes increased network traffic and CPU consumption. Specifying a preferred coordinator server, whenever practical, helps eliminate the need to make frequent coordinator changes... Preferred coordinator servers should be core group processes that are cycled as infrequently as possible. The preferred coordinator servers should also be hosted on machines with excess capacity. " (http://www-01.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/crun_ha_coordinator.html?lang=en) and "Even though it is possible to use a deployment manager as a core group coordinator, it is recommended that you use an application server that is not a deployment manager." (http://www-01.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/trun_ha_cfg_prefcoordinator.html?lang=en).
- Consider tuning some of the HA intervals: http://www-01.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/urun_ha_discov_fail.html?lang=en
If using core group bridges:
- Core group bridges be configured in their own dedicated server process, and that these processes have their monitoring policy set for automatic restart.
- For each of your core groups, you set the IBM_CS_WIRE_FORMAT_VERSION core group custom property to the highest value that is supported on your environment.
- To conserve resources, do not create more than two core group bridge interfaces when you define a core group access point. You can use one interface for workload purposes and another interface for high availability. Ensure that these interfaces are on different nodes for high availability purposes. For more information, see the frequently asked question information on core group bridges.
- You should typically specify ONLY two bridge interfaces per core group. Having at least two bridge interfaces is necessary for high availability. Having more than two bridge interfaces adds unnecessary overhead in memory and CPU.
Large Topology Theory
The WebSphere Application Server Network Deployment product is tuned for small to modest-sized cells in its default configuration. By understanding how the application server components are designed and behave, it is possible to tune the product so that large topologies, which contain hundreds of application servers, can be created and supported.
The primary thing that limits the size of the cell is the need to support shared information across all or a large set of application server processes. The breadth and currency requirements for shared information, which is something that must be known by all or many application server instances within the cell, present a challenge for any distributed computing system.
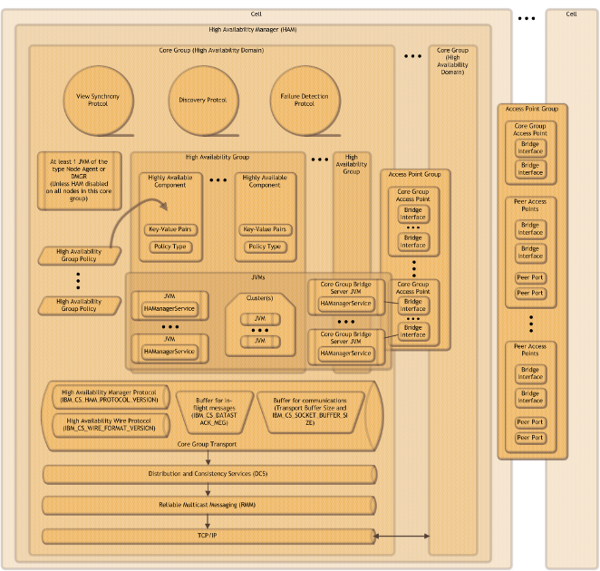
An instance of the High Availability Manager (HAManager) runs inside every process in a Network Deployment cell, including the deployment manager, node agents, application servers and proxy servers. The HAManager provides a set of frameworks and facilities that other WebSphere services and components use to make themselves highly available.
The HAManager relies on core groups. A core group is a collection of firmly coupled processes which collaborate to form a distributed group communication service. It is a requirement that all members of a core group must be in the same cell.
As the size of a cell increases, it may be necessary to partition the cell into multiple core groups, because core groups do not scale to the same degree as other cell constructs. When a cell has been partitioned, it is often necessary to share routing information between core groups. For example, a web application located in core group 1 may call an enterprise bean application located in core group 2. There are also cases where it is necessary to share routing information across cells. A Core Group Bridge provides this capability to extend the HAManager bulletin board beyond core group boundaries. Core groups that are connected with a core group bridge can share routing data.
While there are no WebSphere-defined limits on the size of a core group, there are practical limits. The practical limits are primarily driven by available resources and stability. The amount of resource used by the HAManager and core groups depends on a number of factors, including the core group size, core group configuration settings, the amount of routing data required to support the deployed applications, and quality of service settings.
All members of a core group must be located on machines that are connected by a high speed local area network (LAN). Do not locate members of the same core group on machines that are connected by a wide-area network (WAN). Do not place members of a cell across a firewall, as a firewall provides no meaningful security between members of WebSphere processes.
For active heart-beating, the default configuration settings provide a 30 second heartbeat interval and a 180 second heartbeat timeout, meaning that failovers initiated by the active failure detection mechanism take longer than failovers initiated by socket closing events. This default setting represents a compromise between failover time and background CPU usage. If faster failover is required, then the configured heartbeat timeout can be lowered, at the cost of additional background CPU usage.
The amount of background CPU used by the HAManager for heart-beating and failure detection is affected by the heartbeat interval and core group size. Starting with a core group of 100 members as a baseline using the default heartbeat interval of 30 seconds, approximately 20% of the background CPU used by a WebSphere product application server at idle is spent on heartbeat processing.
Observing a high background CPU at idle can be indicative of the core group (or groups) approaching the practical limit for your infrastructure and deployment. If you encounter high idle CPU, you should explore decreasing the number of members in existing core groups by moving processes to a new bridged core group to reduce the background CPU.
It is a best practice to configure one or more preferred coordinator processes for each core group. This limits the movement of the coordinator and number of state rebuilds. Ideally, assign processes that do not host applications and are located on machines with spare capacity as preferred coordinators.
In a topology that contains core group bridges, it is a best practice to create stand-alone application server processes that do not host applications to function as both bridge interfaces and preferred coordinators.
The limits on the size of a core group are practical, not programmatic. The most important considerations in determining core group sizes are resource usage and stability.
The HAManager uses CPU, memory, and network resources. Generally speaking, memory is not a major factor in determining core group size. The amount of long-term heap memory required for routing data is determined by the topology and applications installed, not by the core group size. Splitting a cell into multiple core groups does not reduce the memory required for the routing data. Therefore, the size of the core group is determined almost exclusively based on the CPU required to establish and maintain the group communication service.
The HAManager uses CPU to establish network connections and group communication protocols between running members of the core group. As processes are started, connections are opened to other core group members and the group membership and communication protocols are updated to include the newly started members in the group, or “View”. This change is often referred to as a “View Change.” As processes are stopped, connections are closed and the group membership and communication protocols are updated to exclude the stopped members.
Therefore, starting or stopping a process causes the HAManager to use CPU to open or close connections and update the group communication service. This means that starting or stopping one process causes some CPU usage by all other running core group members. As the size of the core group grows, the number of connections and size of the group membership will grow, meaning that more CPU will be used for large core groups than for small ones. There is also some short-term usage of heap memory to send the network messages required to update the group communication service.
In general, it is more efficient to start or stop groups of processes at the same time, allowing the HAManager to efficiently consolidate multiple group membership and communication protocol changes within a single view change.
An additional factor to consider is the number of sockets that are consumed to create the connections between core group members. The members of a core group form a fully connected network mesh, meaning every member connects directly to every other member. The total number of sockets used to connect all members of a core group approaches n2, where n is the number of core group members. Suppose for example that you tried to create a core group of 200 members on a single machine. The number of sockets required would be 200 x 199 or 39,800 sockets. The same 200 members split into 4 core groups of 50 members each would require 4 x 50 x 49 or 9800 sockets.
Core groups containing more than 100 members should work without issue in many topologies. Exceeding a core group size of 200 members is not recommended.
Important: Disabling the HAManager might cause some critical functions to fail.
For the reasons outlined previously, rather than disabling HAManager, either create multiple cells or partition the cell into multiple core groups and create bridges. Even if you do not currently use a component that requires HAManger, you may require one at a later time.
IBM_CS_DATASTACK_MEG
In recent versions of WAS, the default values of IBM_CS_DATASTACK_MEG and the transport buffer size are usually sufficient. (http://pic.dhe.ibm.com/infocenter/wasinfo/v8r5/topic/com.ibm.websphere.nd.multiplatform.doc/ae/urun_ha_cg_custprop.html and http://pic.dhe.ibm.com/infocenter/wasinfo/v8r5/topic/com.ibm.websphere.nd.multiplatform.doc/ae/trun_ha_cfg_replication.html)
Setting the two memory sizes does not increase the amount of static heap allocated by the HAManager. These settings affect flow control (how many messages are allowed to pass through the HAManager at any one point in time before we stop sending messages). Larger settings allow more efficient communications. We have seen situations (on large topologies) where having the memory sizes set too small will lead to problems. Generally speaking, the messages have already been allocated by the time they reach the congestion checker so this doesn't give us much relief on the heap issues... increasing the memory sizes has only helped from a stability standpoint.
HAManager Architecture
Previous Section (WAS Classic) | Next Section (Performance Monitoring) | Back to Table of Contents