Servlets
The number of persistent requests per connection may cause a significant throughput improvement, particularly with SSL. In one benchmark, 100% (http://www.ibm.com/developerworks/websphere/techjournal/0909_blythe/0909_blythe.html).
Servers > Application servers > $SERVER > Web container settings > Web container transport chains > * > HTTP Inbound Channel > Select "Use persistent (keep-alive) connections" and "Unlimited persistent requests per connection"
Disable application class and JSP reload checking:
- Enterprise Applications > $APP > Class loading and update detection
- Check "Override class reloading settings for Web and EJB modules"
- Set "Polling interval for updated files" = 0
- Enterprise Applications > $APP > JSP and JSF options
- Uncheck "JSP enable class reloading"
- Save, Synchronize, and Restart
If more than 500 unique URLs are actively being used (each JavaServer Page is a unique URL), you should increase the size of the invocation cache: https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.doc/ae/tweb_url_cache.html
WebContainer Thread Pool
Configure the maximum size of the WebContainer thread pool under Application Servers } $SERVER } Thread Pools } WebContainer } Maximum Size
If system resources allow, it is recommended to set the minimum size of the WebContainer equal to the maximum size because some DirectByteBuffers are cached and kept in thread locals and these are lost if the threads recycle. See http://www-01.ibm.com/support/docview.wss?uid=swg1PK24910
NCSA Access Logs
The HTTP transport channel supports the NCSA access log format to print a line for every HTTP response with various details such as URL (similar to the IHS access log): http://www-01.ibm.com/support/docview.wss?uid=swg21661868.
The original version of WAS NCSA access log did not support custom log formats and did not include the time the response took to be returned. Recent versions support the accessLogFormat custom property which allows a custom format, including %D: The elapsed time of the request in microseconds (https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.doc/ae/rrun_chain_httpcustom.html). This can be used as a lightweight and simple alternative to Request Metrics. This is available starting in WAS 7.0.0.25 (http://www-01.ibm.com/support/docview.wss?uid=swg1PM68250) and WAS 8.0.0.2 (http://www-01.ibm.com/support/docview.wss?uid=swg1PM46717); however, note that there is also an APAR with that function that is required available starting in 7.0.0.29 (http://www-01.ibm.com/support/docview.wss?uid=swg1PM81277). You should also first make sure that APAR PM86708 is applied: http://www-01.ibm.com/support/docview.wss?uid=swg1PM86708
In the WAS Administrative Console:
- Navigate to ${SERVER} > Web Container Settings > Web container transport chains > WCInbound* > HTTP inbound channel
- Note that WCInbound* means applying this whole procedure for each inbound WebContainer transport chain which is used to serve the traffic of interest.
- Check "Enable logging"
- Expand "NCSA Access logging"
- Check "Use chain-specific logging"
- Access log file path = ${SERVER_LOG_ROOT}/http_access.log
- Access log maximum size = 500
- Maximum Number of historical files = 2
- NCSA access log format = Common
- Expand "Error logging"
- Check "Use chain-specific logging"
- Error log file path = ${SERVER_LOG_ROOT}/http_error.log
- Error log maximum size = 500
- Maximum Number of historical files = 2
- Click Apply
- Click "Custom properties"
- Click New...
- Name = accessLogFormat
- Value = %h %i %u %t "%r" %s %b %D
- Click OK
- Save, synchronize, and restart the JVM.
For example, with an accessLogFormat of %h %i %u %t "%r" %s %b %D, an access.log will be written in ${WAS}/profiles/${PROFILE}/logs/ with output such as the following. The last column is the response time of the request in microseconds (divide by 1000 for milliseconds):
127.0.0.1 - - [03/Sep/2014:17:32:33 -0700] "GET / HTTP/1.1" 200 5792 25603The time printed is the time the request arrived, so it is likely that the timestamps will not be in order.
Starting with WAS 8.0.0.11 and 8.5.5.6, the WAS access log supports %{R}W which is the HTTP service time. The difference between the HTTP response time and the HTTP service time is that the former includes the time to send back the entire response, whereas the latter only times up to the first byte sent back. The reason for this distinction is that one very common issue is a slow or bad network, slow client, or slow intermediary proxy (e.g. IHS, etc.). With %D, there is no distinction between the time spent in WAS and the time spent in the network, end-user, and intermediary proxies. %{R}W is a subset of %D and helps isolate where the slowdown may be. This is a heuristic and it doesn't help with servlets that stream responses (and do complex work in between) or otherwise call flush. It also doesn't help if WAS (or the operating system it sits on) has an issue while sending back the rest of the bytes. With those caveats, %{R}W is a great addition to help find where HTTP responses may be slow and you should enable both %D and %{R}W if your version of WAS includes them.
Starting with WAS 8.5.5.5, %{X}W may be used to print the XCT Context ID, if available: http://www-01.ibm.com/support/docview.wss?uid=swg1PI29618
The following POSIX command may be used to review the top 5 slowest requests in the access.log:
$ awk '{print $NF,$0}' access.log | sort -nr | cut -f2- -d' ' | head -5Clone the problemdetermination git repository and run httpchannel.sh (requires Perl and gnuplot) in the same directory as the access.log file:
$ git clone https://github.com/kgibm/problemdetermination
$ problemdetermination/scripts/was/httpchannel.sh access.logExample:
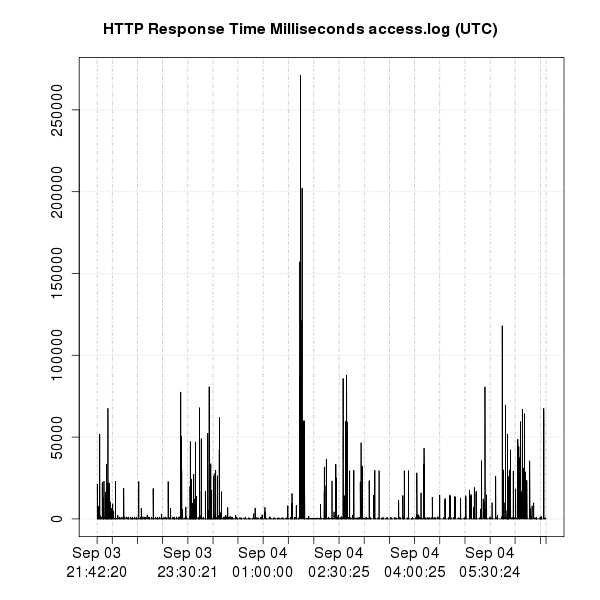
Investigating Response Times
WebSphere Application Server comes with a built-in HTTP(S) server. This section covers different methods of printing the response times of HTTP(S) requests. If all you need are averages, then the built-in Performance Monitoring Infrastructure (PMI) provides average statistics for HTTP(S) response times. However, if you need information on particular requests, then averages may not help. The most robust solution is to use a monitoring product. This will cover the basic capabilities that are built-in to WAS.
Method #0: Web Server logs
This method is not part of WAS, but most use a web server in front of WAS such as the IBM HTTP Server (IHS) or Apache httpd. Servers such as IHS/httpd can log each request and its response time. For example, on IHS/httpd, add %D or %T to your LogFormat to print the response time. Other up-stream load balancers or proxies may have similar capabilities. The rest of this section covers WAS-only methods...
Method #1: Starting in WAS 8.0.0.2, NCSA access log with custom accessLogFormat (see previous section above).
Method #2: Diagnostic Trace
The following diagnostic trace can be used: com.ibm.ws.http.channel.inbound.impl.HttpICLReadCallback=all:com.ibm.ws.http.channel.inbound.impl.HttpInboundLink=all - Change the log details to this for the relevant servers (this can be done dynamically using the Runtime tab). For each request, the following entries will appear in trace.log for a new connection
[9/26/11 16:07:30:143 PDT] 00000029 HttpInboundLi 3 Init on link: com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:30:144 PDT] 00000029 HttpInboundLi > ready: com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7 Entry
[9/26/11 16:07:30:144 PDT] 00000029 HttpInboundLi 3 Parsing new information: com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:30:146 PDT] 00000029 HttpInboundLi 3 Received request number 1 on link com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d
[9/26/11 16:07:30:146 PDT] 00000029 HttpInboundLi 3 Discrimination will be called
[9/26/11 16:07:30:149 PDT] 00000029 SystemOut O SWAT EAR: Invoking com.ibm.Sleep by anonymous (127.0.0.1)... []
[9/26/11 16:07:31:151 PDT] 00000029 SystemOut O SWAT EAR: Done com.ibm.Sleep
[9/26/11 16:07:31:152 PDT] 00000029 HttpInboundLi 3 close() called: com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:31:153 PDT] 00000029 HttpInboundLi 3 Reading for another request...
[9/26/11 16:07:31:153 PDT] 00000029 HttpInboundLi < ready Exit
For an existing connection, it will be slightly different:
[9/26/11 16:07:35:139 PDT] 00000028 HttpICLReadCa 3 complete() called: com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:35:139 PDT] 00000028 HttpInboundLi 3 Parsing new information: com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:35:141 PDT] 00000028 HttpInboundLi 3 Received request number 2 on link com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d
[9/26/11 16:07:35:141 PDT] 00000028 HttpInboundLi 3 Discrimination will be called
[9/26/11 16:07:35:144 PDT] 00000028 SystemOut O SWAT EAR: Invoking com.ibm.Sleep by anonymous (127.0.0.1)... []
[9/26/11 16:07:36:146 PDT] 00000028 SystemOut O SWAT EAR: Done com.ibm.Sleep
[9/26/11 16:07:36:147 PDT] 00000028 HttpInboundLi 3 close() called: com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:36:148 PDT] 00000028 HttpInboundLi 3 Reading for another request...
The time between the "Discrimination will be called" and "close()" lines is when the request/response executed.
Method #3: Request Metrics
Request metrics (also called Application Response Measurement [ARM]) is a standard mechanism for tracking, exposing, and/or logging end-to-end transaction information. However, request metrics has a very large overhead by default unless you use filters (discussed below) and should only be used in a test environment. Request metrics can be enabled in the administrative console under Monitoring and Tuning > Request Metrics. The server does not need to be restarted for request metrics to start working.
- Ensure "Prepare Servers for Request metrics collection" is checked
- Select "Custom" for "Components to be instrumented" and select "Servlet"
- Set "Trace level" to "Hops"
- Check "Standard Logs"
For each JSP and servlet request, the PMRM0003I log entry will be written to SystemOut.log:
[9/26/11 15:43:45:448 PDT] 00000027 PmiRmArmWrapp I PMRM0003I: parent:ver=1,ip=10.20.30.8,time=1317075586068,pid=32507,reqid=1,event=1 - current:ver=1,ip=10.20.30.8,time=1317075586068,pid=32507,reqid=1,event=1 type=URI detail=/swat/Sleep elapsed=1004
The elapsed value at the end of the log line is how long the request took to process and send back the full response, in milliseconds. The detail field has the URL.
If you also select JDBC, you'll get line such as:
[9/26/11 15:49:11:128 PDT] 0000003c PmiRmArmWrapp I PMRM0003I: parent:ver=1,ip=10.20.30.8,time=1323213487261,pid=13311,reqid=1,event=1 - current:ver=1,ip=10.20.30.8,time=1323213487261,pid=13311,reqid=5,event=1 type=JDBC detail=java.sql.Statement.executeQuery(String) elapsed=1
For high volume systems, this can have a huge performance impact, mostly in the overhead of writing to the logs (even with a fast disk, there is also some cross-thread synchronization in logging, etc.). If possible, use the request metrics filters to limit what is logged to particular URLs. Another common technique is to use a source IP filter to a well known user. When an issue occurs, have that user inject their workload and then only those requests will be logged.
Given that request metrics is enabled cell-wide, if you want to disable the SystemOut logging on some servers, you can change the log details for those servers by adding (this can be done dynamically using the Runtime tab): com.ibm.ws.pmi.reqmetrics.PmiRmArmWrapper=off
It is also possible to write your own ARM agent in Java which could, for example, watch for requests that take longer than some threshold, and only print those out to SystemOut.log and/or gather javacores/thread stacks for that request. You would then uncheck "Standard Logs" and instead check "Application Response Measurement(ARM) agent ."
Method #4: IBM -Xtrace
If you want to look at the response times of a particular Java method, and you're using the IBM JVM, then you could use -Xtrace method trace. For example, we know that all HTTP(s) requests for servlets go through javax/servlet/http/HttpServlet.service, so we could use the generic JVM argument:
-Xtrace:methods={javax/servlet/http/HttpServlet.service},print=mt
Every time this method is executed, the following entries will be written to native_stderr.log:
23:21:46.020*0x2b28d0018700 mt.0 > javax/servlet/http/HttpServlet.service(Ljavax/servlet/ServletRequest;Ljavax/servlet/ServletResponse;)V Bytecode method, This = 2b292400fcf8
23:21:47.071 0x2b28d0018700 mt.6 < javax/servlet/http/HttpServlet.service(Ljavax/servlet/ServletRequest;Ljavax/servlet/ServletResponse;)V Bytecode method
Remember that servlets can include other servlets (usually through JSPs), and the method trace entries will be properly indentend, but just make sure you match the right entry and exit to get the correct elapsed time.
Method trace is more useful when you already have some idea of where the slowdown may be. For example, you can specify a list of particular business methods, and then iteratively drill down into those that are slow until you reach the slow method. This of course won't help if the problem is systemic, such as garbage collection, operating system paging, etc., since that will arbitrarily affect any methods. However, it is good at pinpointing backend slowdowns (e.g. put a method trace around database calls).
Method trace changes the way methods are JITted (that's how it's able to instrument any Java method) and it does have a non-trivial performance overhead. This overhead may be slightly minimized by writing the trace to a binary output file instead of as text to stderr.
Other Methods
- If you are using the WebSphere Virtual Enterprise On Demand Router, it has advanced logging capabilities, particularly including filtering to avoid logging overhead.
- If you know when the slowness happens, javadump snapshots are often a good way to determine the slowdown.
- As mentioned in the beginning, although PMI is an average, it does have per-servlet statistics, so that may be able to help pinpoint the slow servlets.
- Adding your own logging entry/exit points around common execution points (for example, if you use a servlet filter or servlet base class) could serve the same function as a custom ARM agent.
WebContainer Channel Write Type
The design of WAS with the default configuration of channelwritetype=async is that WAS will buffer up to the size of each HTTP response in native DirectByteBuffer memory as it waits for asynchronous TCP writes to finish (https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.doc/ae/rweb_custom_props.html). This means that if WAS is serving a large volume of responses from Java servlets (including static files through the WAS FileServlet, servlet/JSP responses, etc.), and if the clients (or the network path leading to the clients) cannot keep up with the pace of network writes, then these DirectByteBuffers will consume the amount of pending writes in native memory. This can cause native OutOfMemoryErrors in 32-bit processes, or paging on 64-bit processes with insufficient physical memory. Even if the network and end-user do keep up, this behavior may simply create a large volume of DBBs that can build up in the tenured area. You may change channelwritetype to sync to avoid this behavior (http://www-01.ibm.com/support/docview.wss?uid=swg21317658) although servlet performance may suffer, particularly for end-users on WANs. A feature request has been opened to change the default behavior: https://www.ibm.com/developerworks/rfe/execute?use_case=viewRfe&CR_ID=53870
Note: With channelwritetype=async, you may see WCChannelLinks waiting to write to the client without any WebContainer thread processing a request. This is expected and is a possibility with asynchronous writing. In this case, what likely happened is that the servlet wrote all of its response to the HTTP channel and finished its use of the thread, and the HTTP channel will asynchronously write the buffered response to the client.
If you have a system dump, in the Memory Analyzer Tool, you can find DirectByteBuffers waiting to be written to the client in the writeQueue java.util.ArrayList under com.ibm.ws.webcontainer.channel.WCChannelLink. In a PHD heapdump, you won't know it is the writeQueue, but that field is the only ArrayList on that object so you know it is the writeQueue. Right click on the ArrayList and click Show Retained Set. Each com.ibm.ws.buffermgmt.impl.PooledWsByteBufferImpl references a DirectByteBuffer, so the number of these instances will correlate with the number of DirectByteBuffers. In a system dump, you can also check the "writing" field on the WCChannelLink to see if that link to the client is still in the process of writing the response.
If you have a system dump and a recent version of the IBM Extensions for Memory Analyzer, in the IBM Memory Analyzer Tool, you can determine the channelwritetype by clicking Open Query Browser > IBM Extensions > WebSphere Application Server > Web Container Analysis.
If you have a system dump, you can find the URL being processed (to review if it may be a large file, for example) and other information such as HTTP headers underneath the WCChannelLink request and response fields.
SSLUtils.flushCloseDown
If you find many threads in a thread dump in the following stack:
at java/lang/Thread.sleep(Native Method)
at java/lang/Thread.sleep(Thread.java:950(Compiled Code))
at com/ibm/ws/ssl/channel/impl/SSLUtils.flushCloseDown(SSLUtils.java:237(Compiled Code))
at com/ibm/ws/ssl/channel/impl/SSLUtils.shutDownSSLEngine(SSLUtils.java:126(Compiled Code))
at com/ibm/ws/ssl/channel/impl/SSLConnectionLink.cleanup(SSLConnectionLink.java:228(Compiled Code))
at com/ibm/ws/ssl/channel/impl/SSLConnectionLink.close(SSLConnectionLink.java:172(Compiled Code))
at com/ibm/ws/http/channel/inbound/impl/HttpInboundLink.close(HttpInboundLink.java:899(Compiled Code))
at com/ibm/wsspi/channel/base/InboundApplicationLink.close(InboundApplicationLink.java:58(Compiled Code))
at com/ibm/ws/webcontainer/channel/WCChannelLink.close(WCChannelLink.java:333(Compiled Code))
at com/ibm/ws/webcontainer/channel/WCChannelLink.releaseChannelLink(WCChannelLink.java:503(Compiled Code)) [...]Then you may consider setting the generic JVM argument -DtimeoutValueInSSLClosingHandshake=0 or the same as an SSL channel custom property.
When this property was introduced, the default wait was indefinite; however, a subsequent fixpack in late 2017 changed the default timeout to 30 seconds.
This stack tends to occur when WAS tries to write the closing SSL handshake and the other side is not reading data, the other side is not closing the connnection, and/or the write buffers are full.
DirectByteBuffer Pools
The WAS WebContainer uses DirectByteBuffers (DBBs) to perform HTTP reads and writes. The use of DBBs is required for good performance. DBBs are used in both cases of channelwritetype=async and channelwritetype=sync. The way DBBs are used is that each WebContainer thread has a lazy-loaded, ThreadLocal pool of DBBs and there is a global pool of DBBs for all WebContainer threads. This is a major reason why it's good for performance to set the minimum size of the WebContainer thread pool to the maximum size because that minimizes the creation and destruction of these DBBs.
The size of the DBB used will depend on the size of the HTTP read or write. Each DBB pool is split into buckets with each bucket having DBBs of a certain fixed size. The default sizes of the DBBs are:
32, 1024, 8192, 16384, 24576, 32768, 49152, 65536
In other words, there is a bucket of DBBs that are each 32 bytes, and a bucket of DBBs that are each 1024 bytes, and so on.
The default sizes of each bucket for a WebContainer ThreadLocal DBB pool are:
30, 30, 30, 20, 20, 20, 10, 10
In other words, there can be up to 30 DBBs of size 32 in the first bucket, up to 30 DBBs of size 1024 in the second bucket, and so on.
The global DBB pool multiplies each of the bucket sizes by 10. In other words, there can be up to 300 DBBs of size 32, and so on.
Therefore, by default, the global pool will use up to ~28MB of DBB native memory, and each WebContainer ThreadLocal DBB pool will use up to ~3MB of DBB native memory.
To determine if the DBB sizes and/or DBB bucket sizes are insufficient, first, ensure that the WebContainer thread pool minimum = maximum, then configure DBB trace (this may have significant overhead, so be careful running in production) with -Xtrace:print=j9jcl.335-338,trigger=tpnid{j9jcl.335,jstacktrace},trigger=tpnid{j9jcl.338,jstacktrace}, run the JVM until the WebContainer thread pool reaches the maximum size, and run the workload until it reaches steady state. If after this point, the DBB trace is still showing allocations from com.ibm.ws.buffermgmt.impl.WsByteBufferPoolManagerImpl.allocateBufferDirect, then consider increasing the DBB and/or bucket sizes. Normally, we only change the bucket sizes (poolDepths) and leave the poolSizes as default.
Another inconclusive but often indirect symptom of DBB pool exhaustion is high global garbage collection pause times with high numbers of PhantomReferences being cleared. The native memory backing DirectByteBuffers is cleared using PhantomReferences, so once a DBB has no more strong references, it is put on a queue like a finalizer. DBBs tend to get tenured, so they can build up in the tenured region of a generational collector and this will hold on to native memory until the next full GC, or if MaxDirectMemorySize is hit, and a large number of queued DBBs may increase global GC pause times (in some implementations, because PhantomReference processing is single threaded).
To modify either the DBB sizes and/or the bucket sizes, edit server.xml (in a network deployment environment, edit in the deployment manager configuration and then synchronize the node(s)):
In the root process:Server element, add the attribute
xmlns:wsbytebufferservice="http://www.ibm.com/websphere/appserver/schemas/6.0/wsbytebufferservice.xmi"Find the services element with the xmi:type loggingservice.http:HTTPAccessLoggingService. After the matching </services> tag, override the DBB sizes and/or the bucket sizes. For example:
<services xmi:type="wsbytebufferservice:WSByteBufferService" xmi:id="WSBBS_1" enable="true">
<properties xmi:id="BuffSVC_4" name="poolSizes" value="32,1024,8192,16384,24576,32768,49152,65536"/>
<properties xmi:id="BuffSVC_5" name="poolDepths" value="100,100,100,20,20,20,20,20"/>
</services>Restart the JVM.
JSP Buffers
The JSP body buffer needs to contain the evaluation of a JSP body tag. The buffer will grow to the size of the body of an action: "The buffer size of a BodyContent object is unbounded." (http://docs.oracle.com/javaee/6/api/javax/servlet/jsp/tagext/BodyContent.html). The property BodyContentBuffSize defines the initial size of each buffer (default 512 bytes) and it's doubled until all of the content is contained. If com.ibm.ws.jsp.limitBuffer=false (the default), the buffer will remain at its latest size for subsequent requests. If com.ibm.ws.jsp.limitBuffer=true, the buffer is reset to BodyContentBuffSize. If the total size of instances of org.apache.jasper.runtime.BodyContentImpl exceeds 5-10% of the maximum Java heap size, then it's recommended to either reduce the application's usage of large JSP body content and/or to set com.ibm.ws.jsp.limitBuffer=true (https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/rweb_custom_props.html).
It's difficult to theoretically calculate an optimal default value for BodyContentBuffSize. If the size is too small, then there is potentially extra time spent growing the buffer. If the size is too large, then there is potentially extra time spent garbage collecting. This is a property used for all JSPs, but if there are multiple JSPs, they will have different characteristics. As with most performance tuning, the best approach is to test different options and find the optimal value using a binary search (ideally first in a test environment): Start with a value X1=512. Continue doubling as long as results improve. Once results are worse, halve the difference from the previous value (X2-X1)/2 and repeat the algorithm (double or halve the difference) until an optimal value is found.
If you have a heapdump, use the Memory Analyzer Tool to calculate the retained set of the class org.apache.jasper.runtime.BodyContentImpl.
If you have a system dump (IBM Java) or HPROF heapdump (HotSpot), then use the following OQL queries in the Memory Analyzer Tool to check the settings of limitBuffer and BodyContentBuffSize:
SELECT x.limitBuffer FROM INSTANCEOF java.lang.Class x WHERE x.@displayName.contains("class org.apache.jasper.runtime.BodyContentImpl ")
x.limitBuffer
trueSELECT x.bodyContentBufferSize FROM org.apache.jasper.runtime.JspFactoryImpl x
x.bodyContentBufferSize
512HTTP gzip compression
HTTP compression can be done either for a request body, or more commonly, for a response body. HTTP compression can only be done if the client sends a request header called Accept-Encoding with an encoding supported by the server:
GET / HTTP/1.1
Accept-Encoding: gzip,deflate...When a response is compressed, the response will have an HTTP header saying how the body is compressed:
HTTP/1.1 200 OK
Content-Encoding: gzip ...WAS does not natively support Content-Encoding such as gzip compression for HTTP responses (except in the proxy server or ODR).
It is recommended to do compression at the web server level (e.g. for IHS, mod_deflate or mod_gzip); however, it may be done by the application within WAS by setting the proper response header and compressing the response content using a custom servlet filter.
Java Server Faces (JSF)
The default setting of org.apache.myfaces.SERIALIZE_STATE_IN_SESSION=true in the version of MyFaces 2.0 that WAS <= 8.5.5 uses may have a significant performance overhead. The default in MyFaces 2.2 has been changed to false. However, note setting this to false causes the state to be stored in browser cookies. If the amount of state is very large, this can cause performance problems for the client-to-server interaction.
The com.sun.faces.util.LRUMap object can hold on to a lot of memory as this is used to hold the various JSF Views in the session. There are two types of JSF Views stored in the session. Logical Views in session and Number of views in session: A logical view is a top level view that may have one or more actual views inside of it. This will be the case when you have a frameset, or an application that has multiple windows operating at the same time. The LOGICAL_VIEW_MAP map is an LRU Map which contains an entry for each logical view, up to the limit specified by the com.sun.faces.numberOfViewsInSession parameter. Each entry in the LOGICAL_VIEW_MAP is an LRU Map, configured with the com.sun.faces.numberOfLogicalViews parameter.
By default the number of views stored for each of these maps is 15. Therefore you can see how it could end up using a lot of memory. The value of com.sun.faces.numberOfViewsInSession and com.sun.faces.numberOfLogicalViews does not have to be "4", it can whatever you feel is adequate for your application.
If either of these parameters are not in the application then it will store up to 15 views in the LRU Maps. Setting these values to something lower will result in lower memory usage by JSF.
The actual number depends on your application. Basically, if we can't find a JSF View in the session to restore we will create a new one. In general, a complex application is one that would allow a user to move back and forth to pages (think something like a wizard), or an application that contains framesets or a lot of pop up windows. For example, if a pop up window is used to fill out some information and then click submit to go back to the original page... that would require storing more views in session.
15 tends to be a high number, especially if the views are large (contains quite a lot of JSF components and their state). One thing to remember is each Logical View can contain the set number of Actual Views. That is where the idea of a frameset comes in -- one logical view for the parent page, and the actual views are the different frames.
More information and how to set the parameters:
- https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.doc/ae/rweb_jsfengine.html
- https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.doc/ae/tweb_jsfengine.html
In particular, com.sun.faces.numberOfViewsInSession and com.sun.faces.numberOfLogicalViews, potentially as low as 4 (the default for both is 15), and com.sun.face.serializeServerState=true
<context-param>
<param-name>com.sun.faces.numberOfViewsInSession</param-name>
<param-value>4</param-value>
</context-param>
<context-param>
<param-name>com.sun.faces.numberOfLogicalViews</param-name>
<param-value>4</param-value>
</context-param>For general MyFaces JSF tuning guidance, see https://wiki.apache.org/myfaces/Performance
MyFaces JSF Embedded JAR Search for META-INF/*.faces-config.xml
By default, the IBM Apache MyFaces JSF implementation searches JSF-enabled applications for META-INF/*.faces-config.xml files in all JARs on the application classpath. A CPU profiler might highlight such tops of stacks of this form:
java.util.jar.JarFile$1.nextElement
java.util.jar.JarFile$1.nextElement
org.apache.myfaces.view.facelets.util.Classpath._searchJar
org.apache.myfaces.view.facelets.util.Classpath._searchResource
org.apache.myfaces.view.facelets.util.Classpath.search
com.ibm.ws.jsf.config.resource.WASFacesConfigResourceProvider.getMetaInfConfigurationResources [...]When an embedded faces-config.xml file is found, a message is written to SystemOut.log with a wsjar: prefix, so this would be a simple way to check if such embedded resource searches are needed. For example:
[10/13/18 4:36:18:481 EST] 00000073 DefaultFacesC I Reading config : wsjar:file:[...]/installedApps/[...]/[...].ear/lib/bundled.jar!/META-INF/faces-config.xmlIf your applications only use a faces-config.xml within the application itself and do not depend on embedded faces-config.xml files within JARs on the application classpath, then you can just disable these searches:
Servers > Server Types > WebSphere application servers > ${SERVER} > Web Container Settings > Web container > Custom Properties > New
Name = com.ibm.ws.jsf.disablealternatefacesconfigsearch
Value = true
https://www.ibm.com/support/knowledgecenter/SSEQTP_8.5.5/com.ibm.websphere.base.iseries.doc/ae/rweb_custom_props.html?view=kc#com.ibm.ws.jsf.disablealternatefacesconfigsearch
If some applications do require embedded faces-config.xml files, then you can disable the search globally, but then enable the search on a per-application basis: https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/tweb_jsfengine.html
HTTP Sessions
The HTTP session timeout is an important factor for how much heap pressure the JVM will face. Work with the business to find the lowest reasonable value (default 30 minutes).
If a customer requires session fail over, use session persistence (database) over memory-to-memory replication. Also, with Liberty Profile v8.5 Extreme Scale is included as a component which can also be used for HTTP session replication see: http://www.ibm.com/developerworks/websphere/techjournal/1301_ying/1301_ying.html; however, it also means managing another set of JVMs and there is risk if those JVMs should be shut down inadvertently. Consider if session failover is required as it increases complexity and decreases performance. The alternative is to affinitize requests and surgically store any critical state into a database: http://www.ibm.com/developerworks/websphere/techjournal/0810_webcon/0810_webcon.html
If using session persistence and a customer can handle timed update semantics, use timed updates: https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.doc/ae/cprs_best_practice.html This is typical for very high volume websites or those with very large HTTP session sizes or both. Again, there is risk even with 10 second intervals of some data loss should a negative event occur. Therefore ensure that the business owners for the application are aware of the risk and their acknowledgment of the risk before switching to timed updates. There is also the option of manual synchronization of sessions but this does involve adding and testing additional code.
The WebSphere Contrarian: Back to basics: Session failover
"My preferred alternative is to rely not on session distribution, but instead to rely simply on HTTP server plug-in affinity to “pin” a user to an application server, although this does mean that stopping an application server JVM will result in the loss of the HttpSession object. The benefit of doing so is that there is no need to distribute the session objects to provide for HttpSession object failover when an application server fails or is stopped. The obvious down side is that a user will lose any application state and will need to log back in and recreate it, and this may or may not be acceptable for your application or business requirements. I'll mention that I’ve worked with a number of customers that in fact agree with this view and make this their standard practice."
Do not enable growable. This will allow WebSphere to ignore the max session pool size and can lead to memory exhaustion (OutOfMemoryExceptions) if capacity is not closely monitored.
Try to keep per-user session data small, ideally less than 4KB (http://www.ibm.com/developerworks/websphere/techjournal/0809_col_burckart/0809_col_burckart.html).
Session overflow of non-distributed/non-persisted sessions is generally a dangerous practice. This creates an unbounded queue for sessions, and it's rarely good to ever have unbounded queues, especially with objects that are often times quite big and long-lived. This can easily cause out of memory errors with sudden spikes of load, and allows for simple Denial of Service (DoS) attacks, whether they be malicious or an errant script. Consider disabling session overflow for non-distributed/non-persistent sessions (by default it is disabled), and adding logic to the application to check for overflow and handle that. Then, sufficient queue tuning, session timeout tuning, and horizontal scaling should be done to support the required number of sessions. When overflow occurs for non-distributed sessions, an instance of a non-null session is returned and it is set to invalid. This can be checked by the application developer.
Database Session Persistence
The write frequency has a large impact on performance: https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.doc/ae/uprs_rtuning_custom.html and https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.doc/ae/uprs_rtuning_parameters.html
Session Data Disappears on Fail Over
In order for HTTP Session fail over to work properly an application has to code their Java objects properly by implementing either Serializable or Externalizable. If the developers fail to do this then when some negative event causes users to fail over to another JVM session data will simply disappear.
Annotation Scanning
Enterprise applications that contain many classes and are enabled for annotations processing (are not marked as "metadata-complete") take extra time to deploy. Extra time is necessary to scan application binaries for annotations that were introduced by Java EE 5. If there are no additional options to limit which classes are scanned, when scanning is enabled for a module all classes in the module must be scanned. A scan of all classes is necessary even when only a small subset of classes within a given module has annotations.
ServletContext.getResource performance
The Java Enterprise Edition 6 (JEE6) specification changed the behavior of ServletContext.getResource to also search for resources in META-INF/resources directories of any JAR files in /WEB-INF/lib:
"[javax/servlet/ServletContext.getResource] will first search the document root of the web application for the requested resource, before searching any of the JAR files inside /WEB-INF/lib." (http://docs.oracle.com/javaee/6/api/javax/servlet/ServletContext.html#getResource%28java.lang.String%29)
WAS starts to implement JEE6 in version 8: https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.doc/ae/rovr_specs.html
If you notice a lot of time spent in ServletContext.getResource (more specifically, com/ibm/ws/webcontainer/util/MetaInfResourcesFileUtils), or significant processing unzipping JARs with that method in the stack, and if you can confirm with your application developers that there are no resources in the JAR files in the WARs, then you can set com.ibm.ws.webcontainer.SkipMetaInfResourcesProcessing = true to revert to JEE5 behavior. Related: http://www-01.ibm.com/support/docview.wss?uid=swg21671090
The custom property com.ibm.ws.webcontainer.metainfresourcescachesize, which defaults to 20, may be used to reduce META-INF/lib searching and JAR processing. If tracing is enabled with com.ibm.ws.webcontainer.util=all., a cache hit will produce the trace entry starting with "got cached META-INF name."
Starting with WAS 8.0.0.10 and 8.5.5.5, additional performance enhancements have been added: http://www-01.ibm.com/support/docview.wss?uid=swg1PI28751
Timeouts
In general, increasing values for timeouts or pool sizes will delay recognition of a downstream component failure, but in the case of pool sizes a larger value also provides some buffering in the event of a failure. As you can see, tuning to prevent your website from stalling in the event of a failure will require a tradeoff between increasing and decreasing various parameters. Arriving at the optimal values for your environment will require iterative testing with various settings and failure scenarios so that you (or at least your computer systems) will be prepared to fail, which in turn should help insure your success (and continued employment). (http://www.ibm.com/developerworks/websphere/techjournal/1111_webcon/1111_webcon.html#sec2)
WebContainer Diagnostic Trace
The following diagnostic trace can be used: com.ibm.ws.http.channel.inbound.impl.HttpICLReadCallback=all:com.ibm.ws.http.channel.inbound.impl.HttpInboundLink=all
For each request, the following entries will appear in trace.log for a new connection
[9/26/11 16:07:30:143 PDT] 00000029 HttpInboundLi 3 Init on link: com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d
com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:30:144 PDT] 00000029 HttpInboundLi > ready: com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d
com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7 Entry
[9/26/11 16:07:30:144 PDT] 00000029 HttpInboundLi 3 Parsing new information: com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:30:146 PDT] 00000029 HttpInboundLi 3 Received request number 1 on link com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d
[9/26/11 16:07:30:146 PDT] 00000029 HttpInboundLi 3 Discrimination will be called
[9/26/11 16:07:30:149 PDT] 00000029 SystemOut O SWAT EAR: Invoking com.ibm.Sleep by anonymous (127.0.0.1)... []
[9/26/11 16:07:31:151 PDT] 00000029 SystemOut O SWAT EAR: Done com.ibm.Sleep
[9/26/11 16:07:31:152 PDT] 00000029 HttpInboundLi 3 close() called: com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d
com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:31:153 PDT] 00000029 HttpInboundLi 3 Reading for another request...
[9/26/11 16:07:31:153 PDT] 00000029 HttpInboundLi < ready ExitFor an existing connection, it will be slightly different:
[9/26/11 16:07:35:139 PDT] 00000028 HttpICLReadCa 3 complete() called: com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:35:139 PDT] 00000028 HttpInboundLi 3 Parsing new information: com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:35:141 PDT] 00000028 HttpInboundLi 3 Received request number 2 on link com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d
[9/26/11 16:07:35:141 PDT] 00000028 HttpInboundLi 3 Discrimination will be called
[9/26/11 16:07:35:144 PDT] 00000028 SystemOut O SWAT EAR: Invoking com.ibm.Sleep by anonymous (127.0.0.1)... []
[9/26/11 16:07:36:146 PDT] 00000028 SystemOut O SWAT EAR: Done com.ibm.Sleep
[9/26/11 16:07:36:147 PDT] 00000028 HttpInboundLi 3 close() called: com.ibm.ws.http.channel.inbound.impl.HttpInboundLink@83d083d
com.ibm.ws.channel.framework.impl.InboundVirtualConnectionImpl@6c706c7
[9/26/11 16:07:36:148 PDT] 00000028 HttpInboundLi 3 Reading for another request...The time between the "Discrimination will be called" and "close()" lines is when the request/response is executed.
IBM Java -Xtrace
If you want to look at the response times of a particular Java method, and you're using the IBM JVM, then you could use -Xtrace method trace. For example, we know that all HTTP(s) requests for servlets go through javax/servlet/http/HttpServlet.service, so we could use the generic JVM argument:
-Xtrace:methods={javax/servlet/http/HttpServlet.service},print=mt
Every time this method is executed, the following entries will be written to native_stderr.log:
23:21:46.020*0x2b28d0018700 mt.0 > javax/servlet/http/HttpServlet.service(Ljavax/servlet/ServletRequest;Ljavax/servlet/ServletResponse;)V Bytecode method, This = 2b292400fcf8
23:21:47.071 0x2b28d0018700 mt.6 < javax/servlet/http/HttpServlet.service(Ljavax/servlet/ServletRequest;Ljavax/servlet/ServletResponse;)V Bytecode methodRemember that servlets can include other servlets (usually through JSPs), and the method trace entries will be properly indented, but just make sure you match the right entry and exit to get the correct elapsed time.
Method trace is more useful when you already have some idea of where the slowdown may be. For example, you can specify a list of particular business methods, and then iteratively drill down into those that are slow until you reach the slow method. This of course won't help if the problem is systemic, such as garbage collection, operating system paging, etc., since that will arbitrarily affect any methods. However, it is good at pinpointing backend slowdowns (e.g. put a method trace around database calls).
Transport Channels
Assuming IHS or ODR is proxying to WAS, change WAS to unlimited persistent incoming connections (second bullet): https://www.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.doc/ae/twve_odralive.html
The default write buffer size for HTTP requests is 32768 bytes. Responses greater than this value trigger an implicit flush, and if no content length was specified, result in the response being sent with chunked Transfer-Encoding. Setting this value much higher probably does not result in significantly fewer actual write() system calls, as the underlying OS buffers are unlikely to accept such large writes. The most interest in this property is not for performance, but as a safety net for response data being written prior to the headers being complete. Or to avoid chunked responses (one-off clients may be confused by some unexpected chunked responses, download progress cannot be estimated, etc). The equivalent buffering in Liberty (there is no Web Container channel) cannot currently be tuned. http://pic.dhe.ibm.com/infocenter/wasinfo/v8r5/topic/com.ibm.websphere.nd.multiplatform.doc/ae/tprf_tunechain.html
The product web container manages all HTTP requests to servlets, JavaServer Pages and web services. Requests flow through a transport chain to the web container. The transport chain defines the important tuning parameters for performance for the web container. There is a transport chain for each TCP port that the product is listening on for HTTP requests. For example, the default HTTP port 9080 is defined in web container inbound channel chain.
The HTTP 1.1 protocol provides a keep-alive feature to enable the TCP connection between HTTP clients and the server to remain open between requests. By default the product closes a given client connection after a number of requests or a timeout period. After a connection is closed, it is recreated if the client issues another request. Early closure of connections can reduce performance. Enter a value for the maximum number of persistent requests to (keep-alive) to specify the number of requests that are allowed on a single HTTP connection. Enter a value for persistent timeouts to specify the amount of time, in seconds, that the HTTP transport channel allows a socket to remain idle between requests. To specify values for Maximum persistent requests and Persistent timeout (Container Settings > Web container > Web container transport chains > Select the normal inbound chain for serving requests. This chain is typically called WCInboundDefault > Click HTTP Inbound Channel (HTTP_2))
Asynchronous I/O (AIO) versus New I/O (NIO)
AIO is the default TCP transport mechanism which is a WAS feature that uses a native library on each operating system to utilize operating system features for asynchronous I/O. An alternative is NIO which is Java's built in asynchronous I/O (also uses native functions in the JVM). Historically, AIO has been disabled primarily to decrease native memory pressures on 32-bit processes running near the edge. There are no clear performance numbers comparing AIO versus NIO. Therefore, this is one of those options that you should test to see what performs better in your case. To switch to NIO: http://www-01.ibm.com/support/docview.wss?uid=swg21366862
In general, AIO should show a marginal performance improvement over NIO because it simplifies some of the selector logic and reduces thread context switching: http://www-01.ibm.com/support/docview.wss?uid=swg21657846
"Prior to WebSphere Application Server V6.x, a one-to-one mapping existed between the number of concurrent client connections and the threads in the Web container thread pool. In other words, if 40 clients were accessing an application, 40 threads were needed to service the requests. In WebSphere Application Server V6.0 and 6.1, Native IO (NIO) and Asynchronous IO (AIO) were introduced, providing the ability to scale to thousands of client connections using a relatively small number of threads. This explains why ... [you may observe] an average [number of] threads [less than the] concurrent client connection [count]." (http://www.ibm.com/developerworks/websphere/techjournal/0909_blythe/0909_blythe.html)
On newer versions of Windows, AIO may have poorer performance: http://www-01.ibm.com/support/docview.wss?uid=swg21681827
AIO may report more concurrently active threads than NIO in the WebContainer thread pool because of a design difference in the way the WebContainer thread pool is used to handle network input/output. In particular, AIO runs ResultHandler Runnables in the WebContainer thread pool which may be idle in the sense that they are waiting for I/O, but are considered active by the WebContainer thread pool because they are actively waiting for AIO results. This behavior is by design and it may only be a concern if the concurrently active thread count is 90% or more of the maximum size of the thread pool. Application performance should primarily be judged by response times and throughput, not by thread pool utilization.
There are two AIO native libraries shipped with WAS: ibmaio and ibmaiodbg (e.g. .so or .dll). If the JVM is started with -DAIODebugNative=true then ibmaiodbg is loaded instead which writes additional debug tracing to traceaio.txt in the JVM's working directory (e.g. profiles/${PROFILE}). This traceaio.txt file does not wrap and cannot be enabled or disabled dynamically. In general, this should be paired with the WAS diagnostic trace *=info:com.ibm.ws.webcontainer.*=all:com.ibm.ws.wswebcontainer.*=all:com.ibm.wsspi.webcontainer.*=all:HTTPChannel=all:GenericBNF=all:TCPChannel=all
With NIO, a dedicated thread does the scheduling for the other WC threads rather than how AIO has each WC thread do scheduling as needed. This may avoid certain AIO deadlock scenarios with persistent connections where all threads are in com/ibm/ws/util/BoundedBuffer.waitPut_ after com/ibm/ws/http/channel/inbound/impl/HttpInboundLink.close
TCP Transport Channel
By default, the TCP transport channel allows up to 20,000 concurrently open incoming connections (Maximum open connections): http://www-01.ibm.com/support/knowledgecenter/SSAW57_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/urun_chain_typetcp.html?cp=SSAW57_8.5.5&lang=en
Benefits of a large value are:
- AIO/NIO intensive work (e.g. most of the time spent reading or writing HTTP responses) can process more concurrent requests.
- There can be more keepalive connections.
- Certain applications have many connections with little activity on each connection.
- Other functions such as asynchronous servlets and WebSockets may require a large number of connections.
Disadvantages of a large value are:
- If there is a backup in the application, host, or external services, too many requests can queue and increase response times without any timeout notification to end-users, unless there are timeouts in upstream proxies (for example, ServerIOTimeout in IHS).
- The number of connections must be supported by operating system and process resource limits such (for example, on a POSIX system, every socket requires a file descriptor and thus the open file ulimit must be large enough).
Keep alive
Both tWAS and Liberty set TCP KeepAlive on TCP channel sockets by default (setKeepAlive(true)).
503 Service Unavailable
WAS will send back a 503 in at least these situations:
- If the WAS HTTP transport channel is stopping or stopped.
- If there is an internal failure when setting up a new connection.
- If the web application containing the target servlet is stopping, stopped, restarting, uninstalled, etc.
An application may send back a 503 response itself, as can other products such as the SIP proxy, Java Proxy Server, On Demand Router, etc.
Apache HttpClient
To isolate your deployment from the OSS framework "Apache HTTP Components" provided by WAS, you would define one or more of the system properties: http://www-01.ibm.com/support/knowledgecenter/SSEQTP_8.5.5///com.ibm.websphere.nd.multiplatform.doc/ae/welc6tech_opensource_isolate.html
For example:
-Dcom.ibm.ws.classloader.server.alwaysProtectedPackages=org.apache.http.
The input will cause the server to block all loadClass() operations on class names containing the package prefix "org.apache.http.". If you need to block getResource() operations on org/apache/http/, then you would also define property:
-Dcom.ibm.ws.classloader.server.alwaysProtectedResources=org/apache/http/
And if you need access to a subpackage of org.apache.http., or a class in org.apache.http., you could define property:
-Dcom.ibm.ws.classloader.server.alwaysAllowedPackages=org.apache.http.subpkg.,org.apache.http.ClassName
Previous Section (Java Database Connectivity (JDBC)) | Next Section (Startup) | Back to Table of Contents