Before you create indexes on tables used by DSS queries, make sure that an index will improve query performance. Generally, DSS queries do not need indexes. In some cases, use of an index can even degrade query performance.
In some cases, however, one or more indexes can improve performance of carefully tuned queries. As you decide whether an index will improve a query, make sure that you factor in the cost of updating the index after tables are updated.
If the column values stored in the index can satisfy the query, the database server does not read the associated table rows. This operation is called a key-only scan. It is faster to omit the page lookups for data pages whenever the database server can read values directly from the index. For example, if an index contains all columns required for a query that uses an aggregate function, such as COUNT or SUM, the database server can return the correct value without accessing the table.
Consider the following simple table and indexes:
CREATE TABLE table (col1 int, col2 int); CREATE INDEX idx_1 on table(col1); CREATE INDEX idx_2 on table(col2);
The optimizer can choose a key-only scan for the following query:
SELECT col1 FROM table WHERE col1 = 10;
However, the optimizer cannot use a key-only scan for the following query because it requires all of the values in the row:
SELECT * FROM table WHERE col1 = 10;
The database server uses multiple-index scans as key-only scans only if the query requests a simple COUNT(*) aggregate on indexed columns. For example, the optimizer might choose to use only the idx_1 and idx_2 indexes to satisfy the following query:
SELECT COUNT(*) FROM table WHERE col1 = 10 AND col2 = 10;
Although the database server returns return counts of key values from multiple-index scans, it does not return the key values themselves. The optimizer cannot use a key-only scan for the following query:
SELECT col1, COUNT(*) FROM table WHERE col1 = 10 and col2 = 10 GROUP BY col1;
Even when the optimizer cannot choose a key-only index scan, however, an index lookup can improve query efficiency by skipping table pages that do not contain any required rows and no table page needs to be read more than once.
At appropriate isolation levels, the query optimizer can use more than one index to read a table in a query under the following circumstances:
If the optimizer chooses to use a GK index, however, it cannot use any other indexes on the same table, including other GK indexes.
In a multiple-index scan, the database server examines only the first column in an index. This means that composite indexes can be used in a multiple-index scan. The database server does not use multiple-index scans in the following kinds of processes:
The database server might be able to use multiple indexes on a single table to reduce I/O to the table itself.
For example if a table T with columns A and B has an index iA on column A and an index iB on column B, the optimizer might choose to use both indexes for queries that require column A and column B in the where clause.
When the database server uses both indexes, it scans index iA and generates a result set RA based on the WHERE clause requirements for column A. The database server also scans index iB in the same way to generate a result set RB. It then merges result sets RA and RB to generate result set R and uses result set R to retrieve the required data rows from table T. Because the merge of the result sets RA and RB into R eliminates many candidate rows, the database server does not need to retrieve table rows simply to evaluate them.
In some cases, however, the optimizer might not choose to use both indexes. The decision depends in part on the selectivity of the column, which the optimizer assesses from the table statistics that the UPDATE STATISTICS statement stores in the system catalog tables.
In the case of an AND operator (where A = ? and B = ?), the optimizer can consider other alternatives. A single index scan is often a better choice because it can be used for several purposes.
In the case of an OR operator (where A = ? OR B = ?), the only alternative is a sequential scan. If the combination of the predicates is less than 10 percent, the optimizer chooses a multiple-index scan if the isolation level permits.
The optimizer might also choose to use multiple indexes on a single table in the following circumstances:
If all of the predicates in the WHERE clause can be evaluated by examining indexes, the database server can count the number of matching rows in the indexes and return the result without accessing the table pages.
To determine the list of rows that satisfy a NOT predicate, the database server can reverse the bitmap values that it obtains by evaluating indexes for a complementary predicate.
Nevertheless, if you can design a single index to meet the needs of your queries, that solution is preferable to creating multiple indexes. The single index can be used for multiple purposes during the same query execution and is less costly to maintain when the table is modified by insert, update, or delete transactions.
The following section describes an example of a multiple-index scan.
The database server uses two indexes to perform the following query:
SELECT * FROM customer WHERE (customer_num = "113" OR customer_num = "119") AND zipcode = "94022";
The database server uses an index on customer_num to retrieve the first set of rows (customer_num = "113" OR customer_num = "119") and an index on zipcode to retrieve the other set of rows (zipcode = "94022"). Without the ability to execute a query using multiple indexes for one table, the database server would probably perform a sequential scan or use only one index.
The following excerpt from the SET EXPLAIN output shows the query path:
from customer
where (customer_num = 113 or customer_num = 119)
and zipcode = "94022"
Estimated Cost: 1
Estimated # of Rows Returned: 1
1) abc_customer: MULTI INDEX PATH
(1) Index Keys: zipcode (Parallel, fragments: ALL)
Index Filter: abc_customer.zipcode = '94022'
AND
(2) Index Keys: customer_num (Parallel, fragments: ALL)
Index Filter: abc_customer.customer_num = 119
OR
(3) Index Keys: customer_num (Parallel, fragments: ALL)
Index Filter: abc_customer.customer_num = 113
To use multiple indexes to execute the query, one or more threads retrieve rows that meet the filter criteria using an index on customer_num, and one or more threads retrieve identifiers of rows that meet the filter criteria using an index on zipcode. The database server converts each stream of row identifiers into a bitmap, performs an AND operation on the bitmaps to produce a final row identifier list, and uses the row identifier list to retrieve the rows from the table.
Whenever possible, the database server stores the combined bitmap in the virtual portion of shared memory. If temporary storage in memory grows too large, the database server might transfer the bitmap to temporary storage on disk.
Specialized indexes might be useful in certain cases.
Bitmap indexes should be created only on columns that contain highly duplicate data, such as a gender or marital status code. The more duplicate values in the key column, the more efficient the bitmap index is. For example, a bitmap index on a key column that can contain only one of two values is extremely efficient. The efficiency of the bitmap index decreases as the number of possible values increases.
Bitmap indexes differ from conventional B-tree indexes in the way that they store duplicate keys. A B-tree index stores a list of row identifiers for any duplicate key value. A bitmap index stores a bitmap for any highly duplicate key value. The bitmap indicates the rows that have the duplicate key value.
To create a bitmap index, include the USING BITMAP keywords in the CREATE INDEX statement, as in the following example:
CREATE INDEX ix1 ON customer(status) USING BITMAP
For information about creating bitmap indexes and estimating their size and efficiency, refer to Estimating Bitmap Index Size.
Bitmap indexes provide the most benefit for queries in the following circumstances:
Consider the following example:
SELECT count(*) FROM customer WHERE zipcode = "85255" AND sales_agent_id = 22;
If the customer table has an index on zipcode and another index on sales_agent_id, the optimizer might use both indexes to execute the query. The database server creates a list of row identifiers that satisfy each part of the query and then compares the list of row identifiers to produce the final result.
Bitmap indexes excel in comparing the result of one part of the query (or predicate) to another part. The process of comparing row identifiers of rows in which zipcode is 85255 to row identifiers of rows in which sales_agent_id is 22 is faster with a bitmap index because the two lists of row identifiers are already in a form that is more efficient to compare.
Bitmap indexes also improve performance for queries that use the COUNT aggregate function. Because it is faster to count bits in a bitmap than to count row identifiers and the table need not be accessed, queries such as the following one perform better with a bitmap index:
SELECT COUNT(*) FROM customer WHERE zipcode BETWEEN "85255" AND "87255" ;
In most other kinds of queries, bitmap indexes are comparable to B-tree indexes. Because bitmap indexes store nonduplicate key values in the same manner as B-tree indexes, performance is the same as if the index were a conventional B-tree index.
If an index has many duplicate values, a bitmap index uses less disk space than a conventional B-tree index. However, the exact savings is hard to estimate because it also depends on how rows that contain the duplicate value are physically spread across the table.
Although the bitmaps are compressed, the size of the compressed bitmap depends upon the pattern of the bitmap. The practical accurate way to determine whether a bitmap index saves space is to create a bitmap index and record its size. Then drop the bitmap index and create a conventional index. Compare the size of the conventional index to the size of the bitmap index.
For more information on estimating the size of a bitmap index, refer to Index Page-Size Estimates.
Generalized-key (GK) indexes expand conventional index functionality to make indexes more useful for optimizing specific DSS queries.
GK indexes store the result of an expression as a key in a B-tree or bitmap index, which can be useful in specific queries on one or more large tables.
GK indexes have the following limitations:
To change a table from STATIC to any other mode, you must first drop all GK indexes on the table.
If you also create other types of indexes on the table, the optimizer might choose to use more than one of these indexes, however.
The three categories of GK indexes are as follows:
A selective index is created with a subquery that selects only a subset of rows from one or more tables.
For example, suppose you have a large table that contains orders. A common query finds the sum of all orders over a certain dollar amount, as follows:
SELECT sum(order_amt) FROM orders WHERE order_amt > 1000 AND order_date > "01/01/97"
If you create a conventional index on order_amt, it contains one key (or row identifier in the case of duplicate keys) for every row. Even a large table fragmented across coservers might have an index with four or five levels. However, you can create a selective index such as the following:
CREATE GK INDEX ix1 ON orders (SELECT order_amt, order_date FROM orders WHERE order_amt > 1000 AND order_date > "01/01/97")
In queries such as the preceding one, the database server can retrieve all qualified rows from index ix1 without reading the table first. On the other hand, with an index on only order_amt, the database server could use the index to retrieve all order amounts greater than 1000, but it must still the read the table data to check that these orders have an order date greater than 01/01/97.
In addition, if you create a selective index, the number of levels created for the index might be reduced, which would decrease the amount of disk I/O.
A virtual-column index contains a key that is derived from an expression. For example, suppose you commonly query on total order cost, which includes merchandise total, tax, and shipping in the following query:
SELECT order_num FROM orders WHERE order_amt + shipping + tax > 1000;
If you add a virtual-column index to that contains the sum of order_amt, shipping and tax, the optimizer might choose to use the index to satisfy this query. The CREATE INDEX statement might be as follows:
CREATE GK index ix2 ON orders (SELECT order_amt + shipping + tax FROM orders);
Without a virtual-column index in this case, the database server must scan the table sequentially to retrieve each row and add up the three columns.
Another use for a virtual-column index is for queries that search on a non-initial substring. Without a GK index, the optimizer cannot take advantage of any index on the column that contains the substring. However, the optimizer can use a GK index created on the same substring as in the query.
The following example shows how queries with noninitial substrings can use a GK index:
CREATE GK INDEX dept ON accts (SELECT code[4,5] FROM accts); SELECT * FROM accts WHERE code[4,5] > '50'
A join index is created by an SQL statement that joins key columns in multiple tables to create keys in an index. The major advantage of using a join index is that the database server precomputes the join results when you create the index, eliminating the need to access some tables that are involved in a query.
You create a join index on one table, referred to here as the indexed table. Any other tables that are involved in the index are referred to as foreign tables.
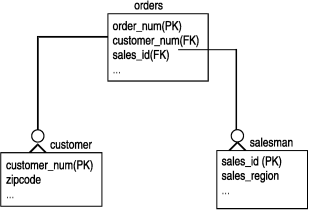
Any foreign tables must be joined by their primary key or a unique key. Figure 25 shows a sample entity-relationship diagram, including tables for which a join index can be used effectively. The indexed table, orders, contains foreign keys that are joined to primary keys in two other foreign tables: salesman and customer. The relationship between the indexed table and the foreign tables is many-to-one, which guarantees that the result of the join is one row.
Suppose that a common query retrieves all of the orders booked by salesmen in a particular region for customers with a specific zip code.
SELECT order_num, order_amt FROM orders, customer, salesman WHERE salesman.sales_region = 20 AND customer.zipcode = 89401 AND orders.customer_num = customer.customer_num AND orders.sales_id = salesman.sales_id
If you create the following index, the customer and salesman tables do not need to be scanned in the previous query, resulting in a large time and resource savings:
CREATE GK INDEX gk_ord_sale_cust ON orders (SELECT salesman.sales_region, customer.zipcode FROM orders, customer, salesman WHERE orders.customer_num = customer.customer_num AND orders.sales_id = salesman.sales_id)
As the following SET EXPLAIN output shows, the query reads only the GK index on orders to fulfill the query:
QUERY: ------ select order_num, order_amt from orders, customer, salesman where salesman.sales_region = 20 and customer.zipcode = 89451 and orders.customer_num = customer.customer_num and orders.sales_id = salesman.sales_id Estimated Cost: 139 Estimated # of Rows Returned: 9 1) sales.orders: G-K INDEX PATH (1) Index Keys: salesman.sales_region customer.zipcode (Parallel, fragments: ALL) Lower Index Filter: (west.salesman.sales_region = 20 AND sales.customer.zipcode = 89451)
For more information on creating a GK index with the CREATE INDEX statement, refer to the IBM Informix: Guide to SQL Syntax.
Home | [ Top of Page | Previous Page | Next Page | Contents | Index ]