For ease and efficiency of management, you can create groups of the coservers that make up the database server and manage disk space and tables in each group as a logical unit. These sets of coservers are called cogroups, which are named lists of coservers. For example, you might create the cogroup sales to manage coservers that contain dbspaces used for your order-entry database.
A predefined cogroup, cogroup_permdata, includes all coservers that can host permanent tables. For information about other predefined cogroups, refer to the IBM Informix: Extended Parallel Server Administrator's Reference.
You can create cogroups and dbslices for the following purposes:
On the coservers included in a cogroup, you create dbslices, which are lists of dbspaces that the database server manages as a single logical storage object.
Consider the table data and the fragmentation scheme for which the dbslice is intended. For example, you might use onutil to create a dbslice from the sales cogroup for the customer table so that the table can be divided into four fragments, one on each coserver for balanced processing and reduced contention:
% onutil 1> CREATE DBSLICE cust_dbslc 2> FROM cogroup sales 3> CHUNK "/dev/dbsl_customer%c" 4> SIZE 490000; DBslice successfully created.
When you create cust_dbslc as shown in the example, the database server creates dbspaces on all /dev/dbsl_customer chunks that have been created across the coservers in the sales cogroup. As the database server creates dbspaces, it names them by combining the dbslice name and an ordinal number. In the previous example, the first dbspace created is cust_dbslc.1, the second is cust_dbslc.2, and so on. If cogroup sales contains coservers 5, 6, 9, and 10, the dbspaces are distributed as follows.
For information about the syntax and options of the onutil commands, refer to the IBM Informix: Extended Parallel Server Administrator's Reference.
A dbslice simplifies the creation of fragmented tables because you can refer to all of the dbspaces for a single table with a single name, the dbslice name. For example, to fragment a table across the dbspaces in the cust_dbslc dbslice, use the following CREATE statement to specify a single dbslice name instead of four dbspace names:
CREATE TABLE customer
(cust_id integer,
...
)
FRAGMENT BY HASH (cust_id)
IN cust_dbslc;
This example shows the customer table fragmented by system-defined hash into all of the dbspaces in the cust_dbslc dbslice.
For information about creating dbslices that increase the possibility of collocated joins, which join table fragments on each local coserver instead of shipping data across the interconnect, see Creating Dbslices for Collocated Joins.
For very large tables, increase the granularity of data to improve query and transaction processing.
For example, if a table uses a hybrid fragmentation scheme that fragments the table on one column by expression into a dbslice and on another column by hash across dbspaces in the dbslice, queries and transactions that select rows based on the fragmenting columns can quickly find required rows without accessing all table fragments.
The following example shows how to use the onutil CREATE DBSLICE command to create a dbslice across 8 coservers in an orders cogroup so that the section of the dbslice on each coserver contains three dbspaces, for a total of 48 dbspaces:
% onutil 1> CREATE DBSLICE orders_sl 2> FROM COGROUP orders 3> CHUNK "/dev/dbsl_orders.%r(1..3)";
The database server creates the following dbspaces on the eight coservers:
coserver dbspace_identifier primary chunk xps.1 orders_sl.1/dev/dbsl_orders.1 xps.1 orders_sl.2/dev/dbsl_orders.2 xps.1 orders_sl.3/dev/dbsl_orders.3 xps.2 orders_sl.4/dev/dbsl_orders.1 xps.2 orders_sl.5/dev/dbsl_orders.2 xps.2 orders_sl.6/dev/dbsl_orders.3 . . . xps.8 orders_sl.22 /dev/dbsl_orders.1 xps.8 orders_sl.23/dev/dbsl_orders.2 xps.8 orders_sl.24 /dev/dbsl_orders.3
The way in which you create a dbslice to distribute the dbspaces across coservers can improve query performance, especially if tables are fragmented to take advantage of collocated joins. A collocated join is a join that is performed locally on one coserver before data is shipped to other coservers for processing.
For example, you might fragment your customer table across five coservers with two disks on each coserver.
If you create a round-robin dbslice as in the following sample onutil command, you gain the advantage of collocated joins because the dbspaces are defined round-robin across coservers rather than in a coserver:
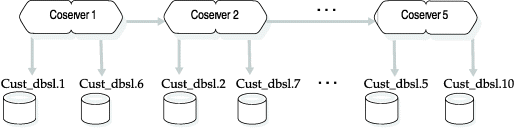
% onutil 1> CREATE DBSLICE cust_dbsl FROM 2> COGROUP sales CHUNK "/dbspaces/dbs1%c" SIZE 490000, 3> COGROUP sales CHUNK "/dbspaces/dbs2%c" SIZE 490000; Dbslice successfully added.
This onutil command creates dbspaces cust_dbsl.1 through cust_dbsl.5 on separate coservers and dbspaces cust_dbsl.6 through cust_dbsl.10 on separate coservers. Figure 4 shows the dbspaces that this onutil CREATE DBSLICE command creates on each coserver.
If you create a dbslice as in the following sample onutil command, queries do not have the advantage of collocated joins:
% onutil 1> CREATE DBSLICE cust_dbsl FROM COGROUP cust_group 2> CHUNK "/dbspaces/dbs%r(1..2)" 3> SIZE 490000; Dbslice successfully added.
This dbslice creation command creates dbspaces cust_dbsl.1 and cust_dbsl.2 on the first coserver, dbspaces cust_dbsl.3 and cust_dbsl.4 on the second coserver, and so forth. Because the database server creates collocated join threads in a round-robin fashion across coservers, queries cannot take advantage of collocated joins with this dbspace layout.
For information about the syntax of the onutil commands, including detailed information about use of wildcards in path names, see the IBM Informix: Extended Parallel Server Administrator's Reference.
Home | [ Top of Page | Previous Page | Next Page | Contents | Index ]