When a query contains more than one table, the database server joins them using filters in the query. For example, in the following query, the customer and orders table are joined by the customer.customer_num = orders.customer_num filter:
SELECT * from customer, orders WHERE customer.customer_num = orders.customer_num AND customer.lname = "Higgins";
The way that the optimizer chooses to join the tables is the join plan. The join method can be a nested-loop join or a hash join.
Because of the nature of hash joins, an application with isolation level set to Repeatable Read might temporarily lock all the records in tables that are involved in the join, including records that fail to qualify the join. This situation leads to decreased concurrency among connections. Conversely, nested-loop joins lock fewer records but provide reduced performance when a large number of rows are accessed. Thus, each join method has advantages and disadvantages.
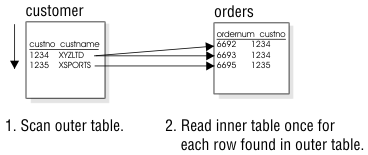
In a nested-loop join, the database server scans the first, or outer table, and then joins each of the rows that pass table filters to the rows found in the second, or inner table. Figure 47 shows tables and rows, and the order they are read, for query:
SELECT * FROM customer, orders WHERE customer.customer_num=orders.customer_num AND order_date>"01/01/1997";
The database server accesses an outer table by an index or by a table scan. The database server applies any table filters first. For each row that satisfies the filters on the outer table, the database server reads the inner table to find a match.
The database server reads the inner table once for every row in the outer table that fulfills the table filters. Because of the potentially large number of times that the inner table can be read, the database server usually accesses the inner table by an index.
If the inner table does not have an index, the database server might construct an autoindex at the time of query execution. The optimizer might determine that the cost to construct an autoindex at the time of query execution is less than the cost to scan the inner table for each qualifying row in the outer table.
If the optimizer changes a subquery to a nested-loop join, it might use a variation of the nested-loop join, called a semi join. In a semi join, the database server reads the inner table only until it finds a match. In other words, for each row in the outer table, the inner table contributes at most one row. For more information on how the optimizer handles subqueries, see Query Plans for Subqueries.
The optimizer usually uses a hash join when at least one of the two join tables does not have an index on the join column or when the database server must read a large number of rows from both tables. No index and no sorting is required when the database server performs a hash join.
A hash join consists of two activities: first building the hash table (build phase) and then probing the hash table (probe phase). Figure 48 shows the hash join in detail.
In the build phase, the database server reads one table and, after it applies any filters, creates a hash table. Think of a hash table conceptually as a series of buckets, each with an address that is derived from the key value by applying a hash function. The database server does not sort keys in a particular hash bucket.
Smaller hash tables can fit in the virtual portion of database server shared memory. The database server stores larger hash files on disk in the dbspace specified by the DBSPACETEMP configuration parameter or the DBSPACETEMP environment variable.
In the probe phase, the database server reads the other table in the join and applies any filters. For each row that satisfies the filters on the table, the database server applies the hash function on the key and probes the hash table to find a match.

The order that tables are joined in a query is extremely important. A poor join order can cause query performance to decline noticeably.
The following SELECT statement calls for a three-way join:
SELECT C.customer_num, O.order_num
FROM customer C, orders O, items I
WHERE C.customer_num = O.customer_num
AND O.order_num = I.order_num
The optimizer can choose one of the following join orders:
For an example of how the database server executes a plan according to a specific join order, see Example of Query-Plan Execution.
Enterprise Edition Home | Express Edition Home | [ Top of Page | Previous Page | Next Page | Contents | Index ]