Methodology
There are various theoretical methodologies such as the USE Method and others which are useful to review.
Begin by understanding that one cannot solve all problems immediately. We recommend prioritizing work into short term (high), 3 months (medium) and long term (low). How the work is prioritized depends on the business requirements and where the most pain is being felt.
Guide yourself primarily with tools and methodologies. Gather data, analyze it, create hypotheses, and test your hypotheses. Rinse and repeat. In general, we advocate a bottom-up approach. For example, with a typical WebSphere Application Server application, start with the operating system, then Java, then WAS, then the application, etc. (ideally, investigate all at the same time).
The following are some example scenarios and approaches. They are specific to particular products and symptoms and they are just a taste of how to do performance tuning. Later chapters will go through the details.
- Poor performance occurs with only a single user: Focus on the component accounting for the most time. Check for resource consumption, including frequency of garbage collections. You might need code profiling tools to isolate the problem to a specific method.
- Poor performance only occurs with multiple users: Check to determine if any systems have high CPU, network or disk utilization and address those. For clustered configurations, check for uneven loading across cluster members.
- None of the systems seems to have a CPU, memory, network, or disk
constraint but performance problems occur with multiple users:
- Check that work is reaching the system under test. Ensure that some external device does not limit the amount of work reaching the system.
- A thread dump might reveal a bottleneck at a synchronized method or a large number of threads waiting for a resource.
- Make sure that enough threads are available to process the work both in IBM HTTP Server, database, and the application servers. Conversely, too many threads can increase resource contention and reduce throughput.
- Monitor garbage collections or the verbosegc option of your Java virtual machine. Excessive garbage collection can limit throughput.
Other useful links:
- If you need tuning assistance, IBM Services provides professional consultants to help.
- On Designing and Deploying Internet-Scale Services
Methodology Best Practices
Methodically capture data and logs for each test and record results in a spreadsheet. In general, it is best to change one varaible at a time. Example test matrix:
Test # Start Time Ramped Up End Time Concurrent Users Average Throughput (Responses per Second) Average Response Time (ms) Average WAS CPU% Average Database CPU% 1 2020-01-01 14:00:00 UTC 2020-01-01 14:30:00 UTC 2020-01-01 16:00:00 UTC 10 50 100 25 25 Use a flow chart that everyone agrees to. Otherwise, alpha personalities or haphazard and random testing are likely to prevail, and these are less likely to succeed. The following is just an example.
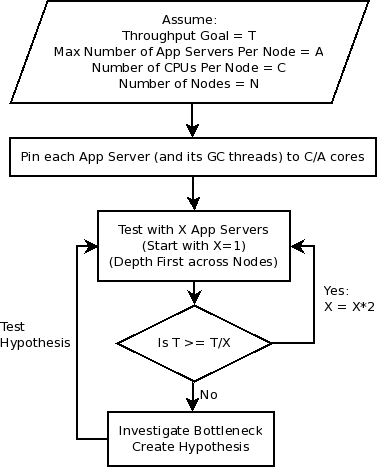
Depth first means first "fill in" application server JVMs within a node before scaling across multiple nodes. The following are example hypotheses that are covered in more detail in each product chapter. They are summarized here just for illustration of hypotheses:- CPU is low, so we can increase threads.
- CPU is low, so there is lock contention (gather monitor contention data through a sampling profiler such as IBM Java Health Center).
- CPU is high, so we can decrease threads or investigate possible code issues (gather profiling data through a sampling profiler such as IBM Java Health Center).
- Garbage collection overhead is high, so we can tune it.
- Connection pool wait times are high, so we can increase the size of the connection pool (if the total number of connections do not exceed the limits in the database).
- Database response times are high (also identified in thread dumps with many threads stuck in SQL calls), so we can investigate the database.
Deeply understand the logical, physical, and network layout of the systems. Create a rough diagram of the relevant components and important details. For example, how are the various systems connected and do they share any resources (potential bottlenecks) such as networks, buses, etc? Are the operating systems virtualized? It's also useful to understand the processor layout and in particular, the L2/L3 cache (and NUMA) layouts as you may want to "carve out" processor sets along these boundaries.
Most, if not all, benchmarks have a target maximum concurrent user count. This is usually the best place to start when tuning the various queue sizes, thread pools, etc.
Averages should be used instead of spot observations. For important statistics such as throughput, getting standard deviations would be ideal.
Each test should have a sufficient "ramp up" period before data collection starts. Applications may take time to cache certain content and the Java JIT will take time to optimally compile hot methods.
Monitor all parts of the end-to-end system.
Consider starting with an extremely simplified application to ensure that the desired throughput can be achieved. Incrementally exercise each component: for example, a Hello World servlet, followed by a servlet that does a simple select from a database, etc. This lets you confirm that end-to-end "basics" work, including the load testing apparatus.
Run a saturation test where everything is pushed to the maximum (may be difficult due to lack of test data or test machines). Make sure things don't crash or break.
Is changing one variable at a time always correct?
It's common wisdom that one should always change one variable at a time when investigating problems, performance testing, etc. The idea is that if you change more than one variable at a time, and the problem goes away, then you don't know which one solved it. For example, let's say one changes the garbage collection policy, maximum heap size, and some of the application code, and performance improves, then one doesn't know what helped.
The premise underlying this wisdom is that all variables are independent, which is sometimes (maybe usually, to different degrees) not the case. In the example above, the garbage collection policy and maximum heap size are intimately related. For example, if you change the GC policy to gencon but don't increase the maximum heap size, it may not be a fair comparison to a non-gencon GC policy, because the design of gencon means that some proportion of the heap is no longer available relative to non-gencon policies (due to the survivor space in the nursery, based on the tilt ratio).
What's even more complicated is that it's often difficult to reason about variable independence. For example, most variables have indirect effects on processor usage or other shared resources, and these can have subtle effects on other variables. The best example is removing a bottleneck at one tier overloads another tier and indirectly affects the first tier (or exercises a new, worse bottleneck).
So what should one do? To start, accept that changing one variable at a time is not always correct; however, it's often a good starting point. Unlesss there's a reason to believe that changing multiple, dependent variables makes sense (for example, comparing gencon to non-gencon GC policies), then it's fair to assume initially that, even if variables may not be truly independent, the impact of one variable commonly drowns out other variables.
Just remember that ideally you would test all combinations of the variables. Unfortunately, as the number of variables increases, the number of tests increases exponentially. Specifically, for N variables, there are (2N - 1) combinations. For example, for two variables A and B, you would test A by itself, B by itself, and then A and B together (22 - 1 = 3). However, by just adding two more variables to make the total four variables, it goes up to 15 different tests.
There are three reasons to consider this question:
First, it's an oversimplification to think that one should always change one variable at a time, and it's important to keep in the back of one's head that if changing one variable at a time doesn't work, then changing multiple variables at a time might (of course, they might also just be wrong or inconsequential variables).
Second, particularly for performance testing, even if changing a single variable improves performance, it's possible that changing some combination of variables will improve performance even more. Which is to say that changing a single variable at a time is non-exhaustive.
Finally, it's not unreasonable to try the alternative, scattershot approach first of changing all relevant variables at the same time, and if there are benefits, removing variables until the key ones are isolated. This is more risky because there could be one variable that makes an improvement and another that cancels that improvement out, and one may conclude too much from this test. However, one can also get lucky by observing some interesting behavior from the results and then deducing what the important variable(s) are. This is sometimes helpful when one doesn't have much time and is feeling lucky (or has some gut feelings to support this approach).
So what's the answer to the question, "Is changing one variable at a time always correct?"
No, it's not always correct. Moreover, it's not even optimal, because it's non-exhaustive. But it usually works.
Keep a Playbook
When a naval ship declares "battle stations" there is an operations manual that every sailor on the ship is familiar with, knows where they need to go and what they need to do. Much like any navy when a problem occurs that negatively affects the runtime environment it is helpful for everyone to know where they need to be and who does what.
Each issue that occurs is an educational experience. Effective organizations have someone on the team taking notes. This way when history repeats itself the team can react more efficiently. Even if a problem does not reappear the recorded knowledge will live on. Organizations are not static. People move on to new projects and roles. The newly incoming operations team members can inherit the documentation to see how previous problems were solved.
For each problem, consider recording each of the following points:
- Symptom(s) of the problem - brief title
- More detailed summary of the problem.
- Who reported the problem?
- What exactly is the problem?
- Summary of all the people that were involved in troubleshooting and what was their role? The role is important because it will help the new team understand what roles need to exist.
- Details of
- What data was collected?
- Who looked at the data?
- The result of their analysis
- What recommendations were made
- Did the recommendations work (i.e. fix the problem)?