Some numeric data types are best suited for counters and codes, some for engineering quantities, and some for money.
The INTEGER and SMALLINT data types hold small whole numbers. They are suited for columns that contain counts, sequence numbers, numeric identity codes, or any range of whole numbers when you know in advance the maximum and minimum values to be stored.
Both data types are stored as signed binary integers. INTEGER values have 32 bits and can represent whole numbers from -231-1 through 231-1.
SMALLINT values have only 16 bits. They can represent whole numbers from -32,767 through 32,767.
The INT and SMALLINT data types have the following advantages:
The disadvantage to using INTEGER and SMALLINT is the limited range of values that they can store. The database server does not store a value that exceeds the capacity of an integer. Of course, such excess is not a problem when you know the maximum and minimum values to be stored.
If you need to store a broader range of values that will fill up an INTEGER, you can use an INT8.
The INT8 data type has the following advantages:
The disadvantage of using an INT8 data type is that it uses more disk space than an INTEGER. IBM Informix Extended Parallel Server (XPS) uses 8 bytes of disk space to store an INT8, IBM Informix Dynamic Server (IDS) uses 10 bytes.
The SERIAL data type is an INTEGER with a special feature. Similarly, the SERIAL8 data type is an INT8 with a special feature. Whenever a new row is inserted into a table, the database server automatically generates a new value for a SERIAL or SERIAL8 column.
A table cannot have more than one SERIAL and one SERIAL8 column. Because the database server generates the values, the serial values in new rows are always different, even when multiple users are adding rows at the same time. This service is useful because it is quite difficult for an ordinary program to coin unique numeric codes under those conditions.
The SERIAL data type can yield up to 231-1 positive integers. Consequently, the database server uses all the positive serial numbers by the time it inserts 231-1 rows in a table. For most users the exhaustion of the positive serial numbers is not a concern, however, because a single application would need to insert a row every second for 68 years, or 68 applications would need to insert a row every second for a year, to use all the positive serial numbers. However, if all the positive serial numbers were used, the database server would wrap around and start to generate integer values that begin with a 1.
The SERIAL8 data type can yield up to 263 -1 positive integers. With a reasonable starting value, it is virtually impossible to cause a SERIAL8 value to wrap around during insertions.
For SERIAL and SERIAL8 data types, the sequence of generated numbers always increases. When rows are deleted from the table, their serial numbers are not reused. Rows that are sorted on a SERIAL or SERIAL8 column are returned in the order in which they were created.
You can specify the initial value in a SERIAL or SERIAL8 column in the CREATE TABLE statement. This makes it possible to generate different subsequences of system-assigned keys in different tables. The stores_demo database uses this technique. In stores_demo, the customer numbers begin at 101, and the order numbers start at 1001. As long as this small business does not register more than 899 customers, all customer numbers have three digits and order numbers have four.
A SERIAL or SERIAL8 column is not automatically a unique column. If you want to be perfectly sure that no duplicate serial numbers occur, you must apply a unique constraint (see Using CREATE TABLE). If you define the table using the interactive schema editor in DB-Access, it automatically applies a unique constraint to any SERIAL or SERIAL8 column.
The SERIAL and SERIAL8 data types have the following advantages:
The SERIAL and SERIAL8 data types have the following disadvantages:
The database server sets the starting value for a SERIAL or SERIAL8 column when it creates the column (see Using CREATE TABLE). You can use the ALTER TABLE statement later to reset the next value, the value that is used for the next inserted row.
You can set the next value to any value higher than the current maximum. Doing this will create gaps in the sequence.
If you try to set the next value to a value smaller than the highest value currently in the column you will not get an error but the value will not be set. Allowing the next value to be set lower than some values in the column would cause duplicate values in some situations and is therefore not allowed.
In scientific, engineering, and statistical applications, numbers are often known to only a few digits of accuracy, and the magnitude of a number is as important as its exact digits.
Floating-point data types are designed for these kinds of applications. They can represent any numerical quantity, fractional or whole, over a wide range of magnitudes from the cosmic to the microscopic. They can easily represent both the average distance from the earth to the sun (1.5 ¥ 1011 meters) or Planck's constant (6.626 ¥ 10-34 joule-seconds). For example,
CREATE TABLE t1 (f FLOAT); INSERT INTO t1 VALUES (0.00000000000000000000000000000000000001); INSERT INTO t1 VALUES (1.5e11); INSERT INTO t1 VALUES (6.626196e-34);
Two sizes of floating-point data types exist. The FLOAT type is a double-precision, binary floating-point number as implemented in the C language on your computer. A FLOAT data type value usually takes up 8 bytes. The SMALLFLOAT (also known as REAL) data type is a single-precision, binary floating-point number that usually takes up 4 bytes. The main difference between the two data types is their precision.
Floating-point numbers have the following advantages:
The main disadvantage of floating-point numbers is that digits outside their range of precision are treated as zeros.
The DECIMAL(p) data type is a floating-point data type similar to FLOAT and SMALLFLOAT. The important difference is that you specify how many significant digits it retains. The precision you write as p can range from 1 to 32, from fewer than SMALLFLOAT up to twice the precision of FLOAT.
The magnitude of a DECIMAL(p) number can range from 10-130 to 10124. The storage space that DECIMAL(p) numbers use depends on their precision; they occupy 1 + p/2 bytes (rounded up to a whole number, if necessary).
Do not confuse the DECIMAL(p) data type with the DECIMAL(p,s) data type, which is discussed in the next section. The DECIMAL(p) data type has only the precision specified.
The DECIMAL(p) data type has the following advantages over FLOAT:
The DECIMAL(p) data type has the following disadvantages:
Most commercial applications need to store numbers that have fixed numbers of digits on the right and left of the decimal point. For example, amounts in U.S. currencies are written with two digits to the right of the decimal point. Normally, you also know the number of digits needed on the left, depending on the kinds of transactions that are recorded: perhaps 5 digits for a personal budget, 7 digits for a small business, and 12 or 13 digits for a national budget.
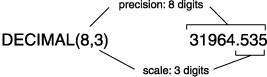
These numbers are fixed-point numbers because the decimal point is fixed at a specific place, regardless of the value of the number. The DECIMAL(p,s) data type is designed to hold decimal numbers. When you specify a column of this type, you write its precision (p) as the total number of digits that it can store, from 1 to 32. You write its scale (s) as the number of those digits that fall to the right of the decimal point. (Figure 23 shows the relation between precision and scale.) Scale can be zero, meaning it stores only whole numbers. When only whole numbers are stored, DECIMAL(p,s) provides a way of storing integers of up to 32 digits.
Like the DECIMAL(p) data type, DECIMAL(p,s) takes up space in proportion to its precision. One value occupies (p +3)/2 bytes (if scale is even) or (p + 4)/2 bytes (if scale is odd), rounded up to a whole number of bytes.
The MONEY type is identical to DECIMAL(p,s) but with one extra feature. Whenever the database server converts a MONEY value to characters for display, it automatically includes a currency symbol.
The advantages of DECIMAL(p,s) over INTEGER and FLOAT are that much greater precision is available (up to 32 digits as compared to 10 digits for INTEGER and 16 digits for FLOAT), and both the precision and the amount of storage required can be adjusted to suit the application.
The disadvantages of DECIMAL(p,s) are that arithmetic operations are less efficient and that many programming languages do not support numbers in this form. Therefore, when a program extracts a number, it usually must convert the number to another numeric form for processing.
Each nation has its own way to display money values. When an Informix database server displays a MONEY value, it refers to a currency format that the user specifies. The default locale specifies a U.S. English currency format of the following form:
$7,822.45
For non-English locales, you can use the MONETARY category of the locale file to change the current format. For more information on how to use locales, see the IBM Informix: GLS User's Guide.
To customize this currency format, choose your locale appropriately or set the DBMONEY environment variable. For more information, see the IBM Informix: Guide to SQL Reference.
Home | [ Top of Page | Previous Page | Next Page | Contents | Index ]