Pipe staging is the process of writing simple large objects to a temporary file when they are too large to fit in memory. The database server uses staging with simple large objects when all of the following conditions apply:
Data read in from a pipe does not persist on disk. The database server does not stage simple-large-object data from disk files because the data can be retrieved from disk if the row overflows the memory buffer.
Because a table in Informix internal format places simple large objects after the row rather than in it, the database server does not stage data when it reads a table with this format.
The database server must reach the end of the row when it evaluates filters or determines which coserver the row will go to based on the fragmentation scheme of the table. The database server temporarily buffers the row.
The reader thread handles the staging of simple large objects to disk. The onstat command and the SET EXPLAIN ON output display this reader thread as the SQL operator xlread, which means load reader.
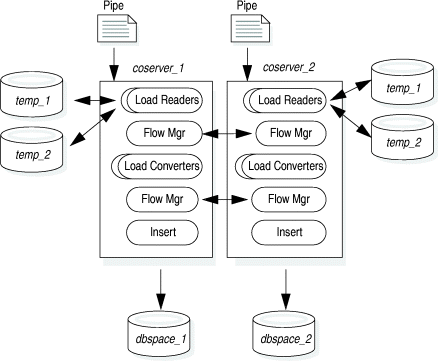
The database server creates multiple xlread instances on each coserver, but no more than the number of CPU virtual processors. Figure 82 shows how multiple xlread instances on each coserver might handle the pipe staging.
The database server creates multiple xlread instances for parallel execution. You need temporary space for each xlread instance.
When you load simple large objects from named pipes in delimited format, you might need to increase the temporary space if the simple large objects are large. If a delimited row is larger than 136 kilobytes, the load routine stages it to disk.
The database server uses temporary space for the staging file. You can use one of the following temporary spaces for the staging files:
The load routine uses these by default. The default value for the DBSPACETEMP configuration parameter is NOTCRITICAL, which includes all dbspaces except the root and log dbspaces. The database server uses temporary dbspaces first among these noncritical dbspaces.
You can specify these in the DBSPACETEMP configuration parameter.
You can override the DBSPACETEMP configuration parameter with this environment variable.
For the following reasons, Informix recommends that you use DBSPACETEMP instead of the PSORT_DBTEMP environment variable to provide temporary file space:
When dbspaces reside on character-special devices (also known as raw disk devices), the database server uses unbuffered disk access. I/O is faster to raw devices than to regular (buffered) operating-system files because the database server manages the I/O operation directly.
These operating-system files can unexpectedly fill on your computer because the database server does not manage them and the database server utility programs do not monitor them.
bytes_per_xlread = row_size + overhead
Estimate overhead as 34 kilobytes rounded up to the next whole page for each 34 kilobyte of TEXT or BYTE data. Page size is user configurable, with a default of 4 kilobytes. With a page size of 4 kilobytes, each 34 kilobytes of data uses 36 kilobytes of temporary space. Therefore the 40-kilobyte simple large object would require 72 kilobytes of space.
The preceding formula is most accurate for rows larger than 1 megabyte. For smaller rows, the row might overflow the 136-kilobyte buffer because part of it might be in the memory buffer while the rest is in the staging file. With larger rows, the buffer size is relatively insignificant.
tempspace_per_coserver = bytes_per_xlread * number_xlr
The number of xlread instances is not more than the number of data files or the number of CPU virtual processors.
For information about monitoring temporary space for pipe staging, refer to Monitoring Loads and Unloads of Data.
Home | [ Top of Page | Previous Page | Next Page | Contents | Index ]