Three primary hardware components make up a database server system:
This section provides some general information and suggestions about configuration and tuning of these hardware components as background information for the database server configuration guidelines.
It is hard to tune system memory, but relatively easy to find out if it is a limiting resource. For information about determining whether memory is a limiting resource in a database server and monitoring large users of memory, Monitoring Table and Fragment Use.
Additional memory does not help a compute-bound system. Database servers store accessed data in memory to avoid disk reads and writes. If you have an I/O or processing problem, adding memory does not improve performance.
The database server provides several features that help you make sure that memory is used efficiently by queries and transactions.
For good I/O performance, plan for the workload you expect and understand the difference between bandwidth and throughput. Increasing bandwidth maximizes the number of megabytes of data processed per second at the cost of the number of reads and writes per second (I/O). Increasing throughput maximizes the number of disk reads and writes per second at the cost of megabytes per second.
DSS workloads are bandwidth intensive, while Web and OLTP workloads are throughput intensive. For example:
Although you probably cannot provide peak performance for both kinds of database applications, analysis of client application patterns can help you decide on a reasonable compromise. Consider trade-offs carefully, however.
When you set up disks for Extended Parallel Server database servers, consider the following suggestions:
If possible, place these objects on private disks for which access is spiral write. A 7200 rpm private disk can make over 300 accesses per second to a logical log. Configured in this way, the logs and system data stored in the root dbspace do not create a bottleneck.
Regardless of the characteristics of the disk drive, store critical information on separate disks from database tables.
Create as much temporary space as possible, especially for DSS systems. For information, see the guidelines in Managing Temporary Space.
You can use relatively slow disks for temporary space, but make sure that DSS applications have a minimum of twice as much temporary space as permanent data space.
Consider the following examples of a fact table layout for a fact-dimension schema:
With 39 disks available on a single coserver, fragment the fact table by week across only seven disk drives. Each dbspace contains multiple chunks. The number of scan threads and other parallel processes depends on the number of dbspaces and the I/O waits increase because all data is on only seven disks.
With the same 39 disks, fragment the table by week across all 39 disks using multiple dbspaces in a dbslice instead of seven dbspaces that contain multiple chunks. With this layout, more scan threads and other parallel processes can run and I/O is more efficient.
Creating dbslices and hybrid fragmentation schemes, as described in Hybrid Fragmentation, makes it easy to continue to fragment the table by week, and improves the possibility of fragment elimination.
If you spread the I/O load across all disks, both parallel processing and I/O efficiency improve performance. For appropriate fragmentation schemes, see Choosing Fragmentation Schemes.
For information about monitoring and adjusting I/O, see Tuning I/O for Tables and Indexes.
Most large database systems use disk arrays that allow hardware mirroring and transparent failover for disk failures. Use of disk arrays means, however, that it is no longer possible to place a table at a specific offset on a specific physical disk or even to identify the physical disk where a table fragment resides.
To understand how to use RAID and fragmentation, consider the following RAID terms:
In a RAID configuration, a block is contiguous virtual disk storage mapped to physically contiguous disk storage on a single member disk in the array.
A stripe is a set of blocks in corresponding positions across member disks in the disk array. A stripe is a logical unit (LUN) in the disk array. The RAID software should allow logical partitioning of the disks and user configuration of chunk and stripe sizes.
The database server cannot distinguish raw disk allocations on RAID virtual disks from allocations on traditional disks. The system administrator and database administrator must work together to ensure that logical volumes defined for use by the database server are properly aligned across the physical disk members.
The simplest method is to specify a volume size that is a multiple of the RAID block size, and the starting address of the volume is a multiple of the block size.
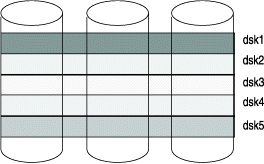
For example, in the RAID system shown in Figure 1, all logical units (LUN) or volumes are made up of blocks of the same size, so that the offset of each block in the volume is a multiple of the chunk size. To take advantage of I/O efficiency and fragment elimination, create chunks for database server storage spaces so that they match the RAID block size. Use the appropriate multiple of the block size as the offset into the logical volume. For information about creating chunks for storage spaces, see Planning Storage Spaces to Support Fragmentation Schemes.
When placing table fragments on RAID devices, consider the logical unit level instead of the physical level. Place fragments of the same table on separate logical units, and also place fragments of tables that are commonly joined on separate logical units.
To maximize I/O throughput, try to achieve the following goals:
For more information, see Managing Data Buffers.
For more information, see Tuning Read-Ahead Behavior, Light Scans, and Light Appends.
For more information, see Planning a Fragmentation Strategy.
Although you cannot tune a CPU, you can maximize the efficiency of CPUs in the following ways:
Configure a database server in which CPUs are divided optimally among coservers.
The database server is designed to use coservers to encapsulate functionality for efficiency. If you have a large SMP system, benchmarks and customer experience generally suggest creating more than one coserver. For DSS applications, an optimal number of CPUs for each coserver is between four and eight. For an SMP system with 24 CPUs, for example, you will probably get the best performance if you create three or four coservers. However, for OLTP applications, you might create only one or two large coservers.
Because optimization of other resources usually increases the CPU load, examine CPU use after other resource use is tuned. Focus on maximizing CPU use in the following ways:
The user state time is the amount of time the CPU spends running the application in user state. It is under the programmer's control and is determined by program-language effectiveness and programmer efficiency.
System state CPU time is the amount of time the CPU spends executing system code on behalf of the application. This includes time spent executing system calls and performing administrative functions for the application.
If there is CPU idle time or the potential to eliminate waits for I/O, it might be possible to accomplish more work.
Use the UNIX sar utility to report CPU utilization information. CPU utilization is the proportion of time that the CPU is busy in either user or system state. Generally, the CPU is idle only when there is no work to be performed or all processes are waiting for I/O resources to complete operations. CPU utilization is the CPU busy time divided by the elapsed time. If the CPU is busy 90 seconds over a 100 second interval, the CPU utilization is 90%.
For information about monitoring compute resources, see your operating system documentation.
Home | [ Top of Page | Previous Page | Next Page | Contents | Index ]