This section describes each fragmentation method and lists its advantages and disadvantages for fragment elimination and even data distribution. For syntax information, see the CREATE TABLE section of the IBM Informix: Guide to SQL Syntax.
A round-robin fragmentation scheme places rows as they are inserted one after another in fragments, rotating through the set of fragments to distribute the rows evenly. If one of the table fragments is full, it is skipped.
Round-robin fragmentation schemes distribute data evenly among table fragments and ensure good performance for applications that require scanning the entire table. Because the database server cannot determine which table fragment contains a specific row, however, round-robin fragmentation schemes have the following significant disadvantages:
Data access through an index requires additional I/O operations and thus might create a performance problem. You might consider a different fragmentation scheme that requires fewer indexes for OLTP applications.
Some DSS queries might need to scan the entire table, but most DSS queries require only a subset of table data. If all table fragments must be scanned for these queries, performance suffers.
Round-robin fragmentation schemes are of limited usefulness. For OLTP applications that execute only short transactions that process few rows through an index, you might use round-robin fragmentation and detach indexes into separate dbspaces. For other applications, consider a fragmentation method that distributes data approximately equally among fragments, but permits the database server to identify fragments that contain specific rows.
An expression fragmentation scheme puts rows that contain specified values in the same fragment. You specify a fragmentation expression that defines criteria for assigning rows to each fragment, either as a range rule or some other arbitrary rule. You can also specify a remainder fragment that holds all rows that do not match the criteria for any other fragment, but a remainder fragment reduces the efficiency of the expression-based fragmentation scheme.
Before you create an expression fragmentation scheme, analyze the data distribution as described in The Data-Distribution Pattern. If you know the data distribution, you can design a fragmentation rule that distributes data across dbspaces as required to meet your fragmentation goal.
The fragmentation expression can be a simple column comparison that has the general form:
<column_name><comparison><constant>
where <comparison> is one of the operators >, >=, =, <=, or <. The following example demonstrates a simple comparison predicate:
FRAGMENT BY EXPRESSION colA < 5 IN db1, colA >= 5 AND colA < 10 db2, ...
The fragmentation can also be a more complex comparison with the general form:
<function(column)><comparison><constant>
In this type of expression, <function> can be one of the following built-in functions:
| Time
Functions |
Arithmetic
Functions |
String-Manipulation
Functions |
Conversion Functions |
|---|---|---|---|
| YEAR | ABS | TRIM | UPPER |
| MONTH | POW | SUBSTRING | LOWER |
| DAY | ROOT | SUBSTR | INITCAP |
| MDY | ROUND | REPLACE | HEX |
| WEEKDAY | SQRT | LPAD | LENGTH |
| TRUNC | RPAD |
The following examples demonstrate the types of complex predicates that can be used in fragmentation expressions:
FRAGMENT BY EXPRESSION colA - colB < 5 in db1, colA - colB >=5 AND colA - colB < 10 db2, ... FRAGMENT BY EXPRESSION YEAR(colA - colB) < 2005 IN db1, YEAR(colA - colB) >= 2005 AND YEAR(colA-colB) < 2010 db2,
For detailed information about the syntax of expression-based fragmentation, see the IBM Informix: Guide to SQL Syntax.
For fragment elimination, the fragmentation scheme should match most query filters. For example, a table might be fragmented so that data for the days of the month, such as the first, the second, the third, and so on, are stored in separate fragments.
Fragment elimination occurs in a way that is analogous to the way fragmentation schemes are handled. The left hand side of the query predicate is extended like the left hand side of a fragmentation expression based on syntactic similarity.
The following examples show queries that have fragments eliminated based on similarities between the query predicate and the fragmentation expression:
FRAGMENT BY EXPRESSION YEAR(order) < 1900 IN db1, YEAR(order) >= 1900 AND YEAR(order) < 2000 IN db2,... SELECT ... WHERE YEAR(order) < 1980;
FRAGMENT BY EXPRESSION paiddate - shipdate < 30 IN db1, paiddate - shipdate > 30 IN db2,... SELECT ... WHERE paiddate - shipdate > 60;
When a query is expressed using different datetime measurements, it can often be transformed into a comparable type which can be used in fragment elimination. The following examples demonstrate how datetime measures are transformed:
FRAGMENT BY EXPRESSION YEAR(order)<1900 IN db1, YEAR(order)>=1900 AND YEAR(order)<2000 IN db2,...--unit in year SELECT ...WHERE order >'05/31/1998 ' ;--unit in date
In this example the fragmentation scheme uses an extraction function such as YEAR(). Here, the same function is applied to both the left hand side of the query and the left hand side of the fragmentation predicate. In the case, the function can be used for fragmentation elimination because it can be applied to both sides of the query predicate. In other words, WHERE order > '05/31/1998'; becomes WHERE YEAR(order) > YEAR('05/31/1998') for the purpose of fragment elimination.
FRAGMENT BY EXPRESSION order < '04/31/1900' IN db1, order >= '06/31/1950' AND order < '01/31/1960' IN db2, ... -- unit in date SELECT ... WHERE YEAR(order) > 1960; -- unit in year
These examples show a context where the left hand side of the query predicate uses an extraction function which matches the left hand side of the fragmentation predicate. If the unit of measure returned by the extraction function can be represented as a range of values that matches the fragmentation scheme, then query optimizer transforms the right hand side of the query predicate into the corresponding range of values. This predicate can the be used for fragment elimination.
A fragmentation expression that generates a relatively even distribution of rows across fragments might improve parallel processing of table fragments if all fragments are required by most queries.
Analyze the queries that access the table, as described in The Table-Access Pattern.
If certain rows are accessed more often than others, try to distribute data so that few of these rows are in the same table fragment.
If all columns are used in many transactions, fragmentation expressions based on more than one column can improve fragment elimination. For example, you might create a hybrid fragmentation scheme, fragmenting the table across coservers with an expression-based scheme and across dbspaces within each coserver with a hash-based scheme.
A hash fragmentation scheme uses an internal hash function to distribute rows among table fragments. If the fragmentation column contains few duplicate values, a hash fragmentation scheme balances the number of rows in each fragment reasonably well.
Because hash fragmentation schemes allow the database server to identify the fragment in which a specific row is placed, such fragmentation schemes are better than round-robin distribution. Table fragments can be identified immediately for OLTP transactions that require only a few rows and eliminated if they are not necessary for DSS queries.
An optimal fragmentation strategy for a DSS-only environment is to fragment tables across all coservers by system-defined hash on a key that is often used to join the tables. When you fragment tables by hash on one column, try to sure that the table fragments are stored in dbslices have been created to take advantage of collocated joins, as explained in Creating Dbslices for Collocated Joins.
Although you can specify a serial column in the hash fragmentation scheme of a fragmented table, it must be the only column that you specify.
Serial values that are assigned to the serial column in a fragmented table and a nonfragmented table might differ. The database server assigns serial values in each fragment, but gaps in the sequence might occur. The values do not overlap. You cannot specify what values to use. The database server controls the values to add.
Hybrid fragmentation schemes, described in the following section, provide additional granularity for fragment elimination.
For detailed information about the syntax of hash fragmentation, see the IBM Informix: Guide to SQL Syntax.
Hybrid fragmentation schemes combine two fragmentation strategies on the same table for increased data granularity and fragment elimination during query processing.
Hybrid fragmentation provides a two-dimensional fragmentation scheme; a table is fragmented by expression or range into specific dbslices or sets of dbspaces and fragmented by hash into the dbspaces in each dbslice or set of dbspaces. This distribution strategy provides finer granularity of table fragments and permits the database server to eliminate fragments based on the hash distribution, the expression distribution, or occasionally both.
For even finer granularity on a single column, you can use the same column as the distribution column for both the hash and expression distribution.
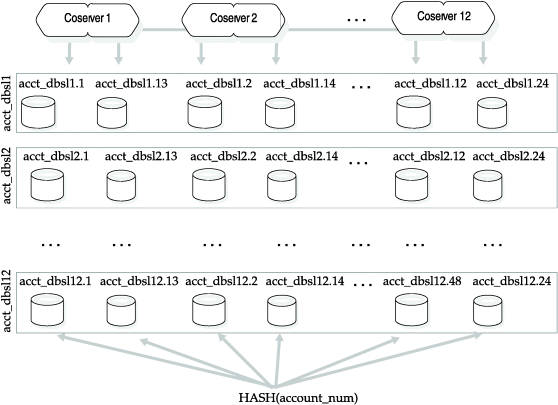
For example, you might use following onutil commands to create the cogroup sales. Then in cogroup sales, you define dbslices across 12 coservers so that each dbslice includes two dbspaces on each coserver for a total of 24 dbspaces:
% onutil 1> CREATE COGROUP sales 2> FROM xps42t_techpubs.%r(1..12); Cogroup successfully added. 3> CREATE DBSLICE acct_dbsl FROM 4> COGROUP sales CHUNK "/dbspaces/dbs1.%c" SIZE 490000, 5> COGROUP sales CHUNK "/dbspaces/dbs2.%c" SIZE 490000; Dbslice successfully added. ... 36> CREATE DBSLICE acct_dbsl12 FROM 37> COGROUP sales CHUNK "/dbspaces/dbs23.%c" SIZE 490000, 38> COGROUP sales CHUNK "/dbspaces/dbs24.%c" SIZE 490000; Dbslice successfully added.
If you have accounting data for a full year, you might fragment account numbers by month, with each month in a separate dbslice. The following CREATE TABLE statement in SQL shows the combination of the expression-based fragmentation scheme to fragment each month into one of the twelve dbslices and the hash fragmentation scheme to fragment the monthly account numbers into the dbspaces in each dbslice:
CREATE TABLE account
(account_num integer,
account_bal integer,
account_date date,
account_name char(30)
)
FRAGMENT BY HYBRID (account_num) EXPRESSION
account_date >= '01/01/1996'
and account_date < '02/01/1996' IN acct_dbsl1
account_date >= '02/01/1996'
and account_date < '03/01/96' IN acct_dbsl2
...
account_date >= '12/01/1996'
and account_date < '01/01/97' IN acct_dbsl12
Figure 2 illustrates the dbspaces in each dbslice for the table fragments that this hybrid fragmentation scheme defines.
For detailed information about the syntax of hybrid fragmentation, see the IBM Informix: Guide to SQL Syntax.
Range fragmentation ensures that rows are fragmented evenly across dbspaces and the fragment that contains each row is uniquely identified. Only columns that contain data of type integer or smallint can be used for range fragmentation expressions, and simple fragmentation can be based on only one column.
Range fragmentation is similar to clustering. It is designed to distribute and cluster rows evenly, and it improves access performance for tables with dense, uniform distributions and little or no duplication in the fragmentation column.
Range fragmentation schemes can be used either as a single-level scheme or a hybrid scheme. Hybrid range fragmentation schemes can specify different columns in each fragmentation statement. For small number ranges, a hybrid range fragmentation scheme might avoid data skew, which sometimes occurs with hybrid hash fragmentation schemes.
Range distribution is similar to expression distribution in that rows are distributed by a range of values. You can use range fragmentation in any circumstance in which expression fragmentation is appropriate and the fragmentation columns are INTEGER or SMALLINT data types.
In range distribution, however, the database server balances the distribution of rows evenly among fragments on the basis of the MIN and MAX values if they are provided or on the assumption that the single stated RANGE value is the maximum and 0 is the minimum.
Equality searches on the search key or keys are faster when rows are grouped in range partitions. For example, queries and transactions with filters of the form WHERE a.col1 = b.col1 or WHERE a.col1 = '12345' can take advantage of the range function on col1 if either table a or b is a range-fragmented table.
The following simple example shows how to create a table with the RANGE fragmentation option. This example shows how to fragment an account lookup table evenly across the ten dbspaces in the dbslice accounts so that each dbspace contains approximately 900 rows. The MIN and MAX keywords indicate the total range of expected values, with account numbers beginning at 1000 and ending at 9999.
CREATE TABLE accth(account_num integer,...) ... FRAGMENT BY RANGE (account_num MIN 1000 MAX 9999) IN accounts;
Range fragmentation can be used in a hybrid fragmentation scheme if the RANGE keyword is used for both fragmentation statements.
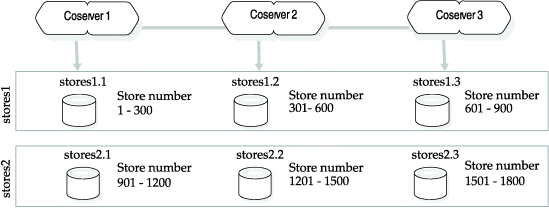
For example, assuming that store numbers are evenly distributed from 1 to 1800 and no store number can be greater than 1800, you might enter the following statement to fragment a file on one column in dbslices across coservers and on the same column through dbspaces in the dbslices on each coserver:
CREATE TABLE stores(store_num integer,...) ... FRAGMENT BY HYBRID (RANGE (store_num)) RANGE(store_num MIN 1 MAX 1800) IN stores1, stores2
Figure 3 shows how the store numbers will be distributed among the dbspaces in the stores1 and stores2 dbslices.
If any values of store_num fall outside of the specified range, 0 to 1800, the database server returns an error and does not insert the rows that contain those values into the table. To prevent such problems, you can specify a REMAINDER fragment in a single dbspace. However, rows in a REMAINDER fragment reduce the efficiency of a range-fragmented table for queries that require range searches.
For finer granularity, you can also use range fragmentation to create a hybrid range fragmentation scheme on two columns. For detailed information about the rules for hybrid range fragmentation, refer to the IBM Informix: Guide to SQL Syntax.
The ALTER FRAGMENT statement is not supported for range-fragmented tables.
For detailed information about the syntax of range and hybrid range fragmentation expressions, see the IBM Informix: Guide to SQL Syntax.
If you find that the original fragmentation scheme is not efficient before you put your database into production, you can change it completely in two ways:
The ALTER FRAGMENT INIT recreates the table with the fragmentation scheme that you specify and moves data as necessary.
When data moves as a result of altering a fragmentation scheme in this way, a logical log record is generated for each moved row. As a result, the transaction might either be aborted as a long transaction or result in many dynamically added logical-log files. In addition, the process might take a long time.
You cannot use the ALTER FRAGMENT INIT statement for a range fragmented table or a STATIC table with a GK index.
For more information about the ALTER FRAGMENT statement, refer to the IBM Informix: Guide to SQL Syntax.
This method is faster than the ALTER FRAGMENT method. If you create the new table definition as a RAW table, reloading data is faster because no logging occurs. Unload table data through an external table definition to an external file, drop the current table, redefine the table with a new fragmentation scheme, and reload the data.
For information about loading and unloading data through, refer to the IBM Informix: Extended Parallel Server Administrator's Guide.
For information about the onutil ALTER DBSLICE command, refer to the IBM Informix: Extended Parallel Server Administrator's Reference.
To change the fragmentation scheme by adding a new fragment, use the ALTER FRAGMENT ATTACH statement, as described in the IBM Informix: Guide to SQL Syntax.