Troubleshooting
Sub-chapters
- Troubleshooting Operating Systems
- Troubleshooting Java
- Troubleshooting WebSphere Application Server
- Troubleshooting Web Servers
- Troubleshooting Containers
- Troubleshooting IBM MQ
- Troubleshooting WXS
Troubleshooting Recipe
- Review the Troubleshoot WebSphere Application Server (The Basics) presentation.
- For troubleshooting tools and performance analysis, review the Self-paced WebSphere Application Server Troubleshooting and Performance Lab presentation.
- While investigating a problem, try to eliminate or reduce any uncontrolled changes to variables such as configuration or application changes. Introduce changes methodically.
- Try to find the smallest, reproducible set of steps that causes the problem.
- If a problem cannot be reproduced in a test environment, consider disallowing real traffic from coming into a particular production node, and then debugging on that node.
The Scientific Method
Troubleshooting is the act of understanding problems and then changing systems to resolve those problems. The best approach to troubleshooting is the scientific method which is basically as follows:
- Observe and measure evidence of the problem. For example: "Users are receiving HTTP 500 errors when visiting the website."
- Create prioritized hypotheses about the causes of the problem. For example: "I found exceptions in the logs. I hypothesize that the exceptions are creating the HTTP 500 errors."
- Research ways to test the hypotheses using experiments. For example: "I searched the documentation and previous problem reports and the exceptions may be caused by a default setting configuration. I predict that changing this setting will resolve the problem if this hypothesis is true."
- Run experiments to test hypotheses. For example: "Please change this setting and see if the user errors are resolved."
- Observe and measure experimental evidence. If the problem is not resolved, repeat the steps above; otherwise, create a theory about the cause of the problem.
Tips
Keep the following in mind, especially if a situation becomes hot:
- Empathize with the stakeholders' situation.
- Be confident and optimistic. You have the scientific method behind you. Except for rare chaotic effects and machine learning systems, computers are basically deterministic and it's simply a matter of time, effort, a sprinkle of creativity, and finding the right people for the problems to be solved. Do your best.
- Ask the stakeholders about the resolution criteria. In some cases, the criteria are obvious, and in other cases, there needs to be some negotiation about reasonable success criteria (which may change over time). In any case, the criteria should be agreed upon in writing and modified in writing when the situation changes. This avoids any misaligned expectations.
- Seek the truths related to the resolution criteria. Deliver the truths sensitively.
- Keep detailed notes about meetings, investigations, tests, etc., and continuously share a summary of those notes with the team and management.
- Save lessons learned in a separate document (e.g. document file, wiki, version control, a copy of this document, etc.) to save time in the future and to share knowledge with others.
- Establish some basic human relationship with the people you're working with by not sounding too much like a lawyer. Be precise and professional, but also be personable and, when appropriate, use inoffensive questions and humor beyond the narrow facts of the situation.
- If you don't know an answer, be honest and say you don't know, and also say that you will do anything in your power to find the answer. Follow-up on any such promises you make.
- Prioritize. There may not be enough time or need to understand every detail or question.
- Be nice.
Initial Engagement
When you're first engaged in a situation, whether in person, by phone, or by email, don't ask too many questions. There are many interesting questions such as "how long has this been happening?" and "what changed?" which are sometimes useful, but often too general, time consuming and inconclusive. This is not to discount experiences people have of asking simple questions and finding simple solutions, but you should optimize for the average case. Use the minimum set of questions that will allow you to gather evidence, create hypotheses, and test those hypotheses.
In addition to understanding the situation, use the first set of questions to make an initial judgement about the skill level and time availability of the people involved. If you perceive high skill level or time availability, then ask more questions and explore the knowledge of the people; otherwise, gather evidence and let the data speak for itself.
Example question list for a first engagement:
- What are the problems and when did they occur?
- What are the impacts on the business?
- Do you observe any specific symptoms of the problems in the WAS logs, application logs, or the operating system or other monitoring tools?
- What versions of software are being used (e.g. WAS, Java, IHS, etc.)? Is the operating system virtualized?
- Are there any workarounds?
- If the problem is in a production environment, can you reproduce it in your test environment?
Based on the answers to these questions, if there are no obvious hypotheses, then the next step is to ask for all available logs.
Analyzing Logs
The most important thing is to always try to analyze all logs as thoroughly as possible on every incident. Make no assumptions. There have been many embarrassing cases where only the logs with the known symptoms were analyzed, and the actual cause was another symptom in other logs the whole time (e.g. FFDC, etc.). Analyzing all logs is also useful to get a fuller understanding of everything happening in the system which may help with creating hypotheses about the problem.
If you find a symptom before or during the problem that may be related, then do the following:
- Prioritize symptoms based on relevance, timing, and frequency.
- Search IBM documentation for the symptom.
- Search internal problem ticket systems, wikis, etc. for the symptom.
- Discuss with other people familiar with the issue or component.
- Use popular search engines to search for the symptom. Use double quotes around the search term for exact matches.
Organizing an Investigation
Keep track of a summary of the situation, a list of problems, hypotheses, and experiments/tests. Use numbered items so that people can easily reference things in phone calls or emails. The summary should be restricted to a single sentence for problems, resolution criteria, statuses, and next steps. Any details are in the subsequent tables. The summary is a difficult skill to learn, so you must constrain yourself to a single (short!) sentence. For example:
Summary
- Problems: 1) Average website response time of 5000ms and 2) website error rate > 10%.
- Resolution criteria: 1) Average response time of 300ms and 2) error rate of <= 1%.
- Statuses: 1) Reduced average response time to 2000ms and 2) error rate to 5%.
- Next steps: 1) Investigate database response times and 2) gather diagnostic trace.
Problems
| # | Problem | Case | Status | Next Steps |
|---|---|---|---|---|
| 1 | Average response time greater than 300ms | TS001234567 | Reduced average response time to 2000ms by increasing heap size | Investigate database response times |
| 2 | Website error rate greater than 1% | TS001234568 | Reduced website error rate to 5% by fixing an application bug | Run diagnostic trace for remaining errors |
Hypotheses for Problem #1
| # | Hypothesis | Evidence | Status |
|---|---|---|---|
| 1 | High proportion of time in garbage collection leading to reduced performance | Verbosegc showed proportion of time in GC of 20% | Increased Java maximum heap size to -Xmx1g and proportion of time in GC went down to 5%; Further fine-tuning can be done, but at this point 5% is a reasonable number |
| 2 | Slow database response times | Thread stacks showed many threads waiting on the database | Gather database response times |
Hypotheses for Problem #2
| # | Hypothesis | Evidence | Status |
|---|---|---|---|
| 1 | NullPointerException in com.application.foo is causing errors | NullPointerExceptions in the logs correlate with HTTP 500 response codes | Application fixed the NullPointerException and error rates were halved |
| 2 | ConcurrentModificationException in com.websphere.bar is causing errors | ConcurrentModificationExceptions correlate with HTTP 500 response codes | Gather WAS diagnostic trace capturing some exceptions |
Experiments/Tests
| # | Experiment/Test | Date/Time | Environment | Changes | Results |
|---|---|---|---|---|---|
| 1 | Baseline | 2020-01-01 09:00:00 UTC - 2020-01-01 17:00:00 UTC | Production server1 | None | Average response time 5000ms |
| 2 | Reproduce in a test environment | 2020-01-02 11:00:00 UTC - 2020-01-02 12:00:00 UTC | Test server1 | None | Average response time 8000ms |
| 3 | Test problem #1 - hypothesis #1 | 2020-01-03 12:30:00 UTC - 2020-01-03 14:00:00 UTC | Test server1 | Increase Java heap size to 1g | Average response time 4000ms |
| 4 | Test problem #1 - hypothesis #1 | 2020-01-04 09:00:00 UTC - 2020-01-04 11:30:00 UTC | Production server1 | Increase Java heap size to 1g | Average response time 2000ms |
| 5 | Test problem #2 - hypothesis #1 | 2020-01-05 UTC | Production server1 | Application bugfix | Average response time 2000ms |
| 6 | Test problem #2 - hypothesis #2 | TBD | Test server1 | Gather WAS JDBC PMI | TBD |
| 7 | Test problem #2 - hypothesis #2 | TBD | Test server1 | Enable WAS diagnostic trace com.ibm.foo=all | TBD |
Site Reliability Engineering
Site Reliability Engineering (SRE) is an approach to computer operations with a focus on continuous delivery, software engineering, automation, a hypothesis and data-driven approach, reducing risk, incident management, performance tuning, capacity planning, and balancing velocity, quality, serviceability, reliability, and availability.
Root Cause Analysis (RCA)
Root cause analysis (RCA) is the search for the primary, sufficient
condition that causes a problem. The first danger of "root" cause
analysis is that you may think you're done when you're not. The word
"root" suggests final, but how do you know you're done? For example,
there was a problem of high user response times. The proximate cause was
that the processors were saturated. The processors were being driven so
heavily because System.gc was being called frequently,
forcing garbage collections. This was thought to be the "root cause" so
somebody suggested using the option -Xdisableexplicitgc to
make calls to System.gc do nothing. Everyone sighed relief;
root cause was found! Not so. The System.gcs were being
called due to native OutOfMemoryErrors (NOOMs) when trying
to load classes (and -Xdisableexplicitgc doesn't affect
forced GCs from the JVM handling certain NOOMs). After much more
investigation, we arrived at a very complex causal chain in which there
wasn't even a single cause:
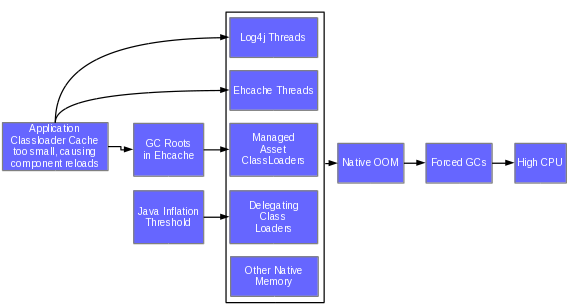
The second danger of root "cause" analysis is that it suggests a single cause, which obviously isn't always the case.
Properly understood and with all the right caveats, RCA is fine, but it is rarely properly understood and rarely comes with caveats. Once someone declares that "root cause" has been found, most people are satisfied, especially if removing that cause seems to avoid the problem. It is interesting that the term "root" has gained such a strong hold, when it is clearly too strong of a term. It's possible that "root" was added to "cause analysis," because without "root," some people might stop at the first cause, but perversely, the phrase has caused the exact same sloppiness, laziness and false sense of accomplishment that it was probably designed to avoid. However, given that both suffer from the same problem, "root cause analysis" is worse than "cause analysis" because at least the latter is more open ended.
Instead, the term "causal chain" is preferred because it seems to define the investigation in terms of a chain of causes and effects and is more suggestive of the open-endedness of this chain graph.
Some popular troubleshooting patterns are the Apollo methodology, Kepner-Tregoe (KT), Five Whys, and others.
Analysis versus Isolation
A common aspect to a problem is that an application worked and then the environment (WAS, etc.) was upgraded and the application stopped working. Many customers then say, "therefore, the product is the root cause." It is easy to show that this is a logical fallacy (neither necessary nor sufficient) with a real world example: A customer upgraded from WAS 6.1 to WAS 7 without changing the application and it started to throw various exceptions. It turned out that the performance improvements in WAS 7 and Java 6 exposed existing concurrency bugs in the application.
It is not wrong to bring up the fact that a migration occurred. In fact, it's critical that you do. This is important information, and sometimes helps to quickly isolate a problem. However, people often make the argument that the fact of the migration is the key aspect to the problem. This may or may not be true, but what it does do is elevate the technique of isolation above analysis, which is often a time-consuming mistake.
Analysis is the technique of creating hypotheses based on observed symptoms, such as exceptions, traces, or dumps. In the above example, the customer experienced java.util.ConcurrentModificationExceptions in their application, but they did not analyze why.
Isolation is the technique of looking at the end-to-end system instead of particular symptoms, and simplifying or eliminating components until the problem is isolated, either by the process of elimination, or by finding the right symptoms to analyze. Saying that the migration is the key aspect to the problem is really saying that the first step is to understand what changed in the migration and then use that to isolate which changed component caused the problem. As the above example demonstrates, changes such as performance improvements may have unknown and unpredictable effects, so isolation may not help.
In general, start with analysis instead of isolation. You should certainly bring up any changes that occurred right before the problem (migration, etc.), but be careful where this leads everyone. If analysis leads to a dead end, then consider using isolation, including comparing changes, but even in this case, comparing product versions is difficult; many things change.
IBM Support
For problems that fall within the scope of your IBM Support Contract (note that some performance issues do not), but cannot be resolved within a reasonable time, we recommend you open a support case through My https://www.ibm.com/mysupport/s/) at the appropriate severity level. What is reasonable will depend on how important the application is to the business and the Service Level Agreements (SLAs) the application is expected to deliver. Note that a support case was previously known as a Problem Management Record (PMR).
After opening a case with IBM Support, we will need data about your specific issue. In order to expedite analysis, WAS provides instructions on the data collection steps for various problem scenarios in a list of MustGathers. Once you have collected the relevant data, upload it to the case. Once IBM has received the data, we will try to provide a response within the designated time criteria depending on the severity level.
If you feel the case needs more attention, call the local toll free number and ask the person who answers the phone to speak with the "duty manager". Provide the duty manager with your case number and the specific issue you feel needs to be addressed.
If you are evaluating WAS software and have not purchased licenses, you cannot open a support case; however, your IBM sales representative, IBM client team, or a business partner may be able to open support cases while working with you.
How to Upload Data to a Case
- Create a single archive per machine with a descriptive name and the
case number and a
README.txtfile that describes relevant events or time periods, replacing commas with periods (e.g.TS001234567.test1.node1.zip). - Follow upload
instructions:
- If the files are less than 20MB in total, and there is no sensitive information, send an email to ecurep@ecurep.ibm.com with the files attached and the subject, "Case TS001234567: Subject of the update"
- If the files are less than 200MB, use the secure browser upload
- Otherwise, use SFTP:
- Prepend file(s) with the case number. For example,
TS001234567_somefile.zip. You may also prepend with "Case"; For example,Case_TS001234567_somefile.zip sftp anonymous@sftp.ecurep.ibm.com- Press
Enterat the password prompt - cd
toibm/websphere - put
TS001234567_somefile.zip
- Prepend file(s) with the case number. For example,
WebSphere Application Server Troubleshooting and Performance Lab
The WebSphere Application Server Troubleshooting and Performance Lab provides a Linux VM with various tools installed as well as WAS itself and a self-paced lab.
Problem Diagnostics Lab Tookit (PDTK)
The Problem Diagnostics Lab Toolkit is an EAR file that can be installed inside WebSphere Application Server and used to simulate various problems such as OutOfMemoryErrors: https://www.ibm.com/support/pages/problem-diagnostics-lab-toolkit
No modes: An exception?
In computing history, there was a famous crusade by Larry Tesler -- a titan of the industry; he worked at Xerox PARC (Smalltalk), Apple, Amazon, and Yahoo -- which he called "no modes." He said, for example, that you shouldn't have to enter a "mode" just to type text. You should be able to click and type. It was a revolutionary idea back then. There are still some popular modal programs today such as vi and Emacs, and the mode combinations make their users look like wizards, but in general, modes are dead.
However, perhaps there should be modes with the rm` (remove) command. Here is an output of the history from a problem situation:
cd /usr/IBM/WebSphere/AppServer/profiles/dmgr
rm -rf heap*
rm -rf javacore *Do you see the mistake? The user wanted to delete all javacore files in the current directory, but accidentally put a space before the wildcard. This resolves to: delete any single file named javacore, and then delete everything else in this directory, recursively! In this case, the -r (recursive) flag was superfluous (since you don't need it when you're just removing files) and did the real damage, as it recursively deleted everything under that directory.
It's hard to blame the person. We've all done similar things. The problem is that after a while you become too comfortable flying through a machine, copying this, deleting that.
There's something about rm that is different. It's hard to slow down sometimes or not to use -f or -r gratuitously. Therefore, perhaps there should be a mode to run rm, and it should be difficult to disable (kernel compile flag?). Your brain needs to do a context switch and give itself time to answer a few questions: What am I deleting? What would I like to delete? Is there a difference between the two?